







Future Tech
[转贴] 北京大模型应用再加码!发创新应用白皮书、点亮公共算力平台、首期中文互联网语料库CCI亮相


智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 李水青
智东西11月29日报道,今天,AICC 2023人工智能计算大会上,北京市公布了大模型应用、算力基础设施、中文数据集三方面的重磅新成果!
1、《北京市人工智能行业大模型创新应用白皮书(2023年)》(以下简称《白皮书》)发布,调研六大领域近百家企业的大模型应用,为大模型产业应用落地提供参考;
《白皮书》链接:https://kw.beijing.gov.cn/art/2023/11/29/art_6382_724110.html
2、海淀区北京人工智能公共算力平台点亮,与智谱华章、紫东太初等首批入驻大模型企业签约;
3、“中文互联网语料库”首期104GB数据公开,数据集时间跨度为2001年1月至2023年11月。
智源开放数据仓库下载地址: https://data.baai.ac.cn/details/BAAI-CCI
HuggingFace下载地址:https://huggingface.co/datasets/BAAI/CCI-Data
国际数据调研机构IDC和算力龙头企业浪潮信息联合发布的《2023-2024年中国人工智能计算力发展评估报告》提到,中国人工智能计算力发展评估城市排行榜的前五名为北京、杭州、深圳、上海、苏州,且北京连续六年排名第一。
从大模型产业的发展情况来看,北京市目前在人工智能创新算力基础、人才资源、研发能力方面都有较大优势,且人工智能核心企业数量、算力基础设施规模、备案大模型数量位居全国第一。
此次发布的一系列重磅成果,正是北京市面向大模型产业发展在算力、数据、应用落地等核心痛点的有利突破。创新成果从北京市大模型企业的实际案例出发,为企业创新发展提供一定的借鉴参考,并从政策层面为产业生态提供支撑。
此前,北京市已经发布了一系列人工智能相关的政策,如《北京市加快建设具有全球影响力的人工智能创新策源地实施方案(2023-2025年)》、《北京市促进通用人工智能创新发展的若干措施》、《人工智能算力券实施方案(2023—2025年)》,这些都已经成为北京市人工智能产业加速发展的重要保障。
一、北京大模型约占全国一半,行业应用四大特点凸显
距离2022年11月30日ChatGPT发布已经一年,大模型带来的技术革新热度不减,与此同时,大模型产业的众多参与者已经将目光从算力投向应用落地。
从国内的大模型产业发展来看,北京市已经成为国内人工智能领域创新基础、人才资源、研发能力都有明显优势的城市之一。根据《白皮书》,2022年北京市人工智能核心产值规模达2170亿元,核心企业数量已经超过1800家,截至2023年10月,我国10亿参数规模以上的大模型厂商及高校院所共计254家,北京拥有其中122家,约占全国的一半。
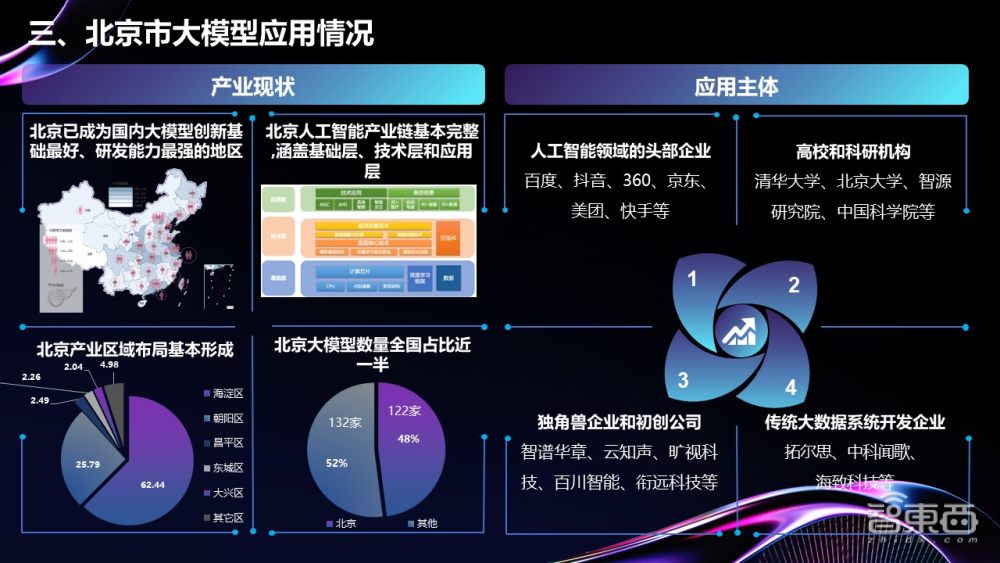
与此同时,大模型应用落地加速之际,北京市众多产业玩家已经在政务、金融、医疗等领域实现落地,并且其布局特点也逐渐清晰。
从模型演进来看,通用大模型已经呈现出强大的泛化能力,但在与各行各业深入融合时,由于缺乏行业深度,无法针对性解决特定行业的实际需求。因此,通过面向特定领域进行大模型训练,打造垂直行业大模型能满足行业特定需求,成为大模型商业化落地的重要方向。
在大模型应用的赛道方面,目前北京市大模型的应用速度较快的领域为传统产业赋能和金融领域,原因在于这两大领域的央国企密集,具有较强的数据基础设施、算力投入和人工智能应用基础,对于推进大模型应用也更加主动。

大模型对于内容理解、生成的能力不断增强,逐渐从文字、图片生成升级到视频、音频、3D动画生成。《白皮书》提到,大模型的应用类型主要有内容生成、智能问答、IT支持、数据分析、智能识别和智能硬件六类。
其中,内容生成和智能问答两个方面的应用类型已经逐渐成熟。面向B端,这两类应用对于行业降本增效、业务价值提升、落地速度的价值体现更为明显,这在一定程度上能够快速完成市场教育,进一步推进大模型应用落地。
在商业模式角度,大模型形成了以通用大模型人工智能服务为主的基础层、以垂直行业领域人工智能服务为主的行业层和以大模型应用服务为主的应用层的“基础+行业+应用”的三层架构。

大模型的商业模式正是通过通用大模型底座的强大能力,与行业细分领域相结合,再将能力集成到实际应用中,从而让大模型的真正社会价值得以体现,并对人们的生活、工作产生影响。
不论从大模型自身能力的升级迭代,还是行业实际痛点来看,大模型商业化落地应用已经迫在眉睫。一些行业先行玩家的应用落地实例,为国内大模型大规模商业化落地提供了经验。
二、调研六大领域近百家企业,AI率先落地传统产业及金融
从北京市的大模型产业应用来看,大模型产业玩家的落地应用集中于政务、金融、医疗、传统产业赋能、文化旅游、智慧城市六大领域。
《白皮书》调研了六大领域中近百家企业的行业大模型应用案例,并梳理出其中18个典型案例,从不同领域的特点出发,结合企业的实际案例,以此整合出当下北京市行业大模型商业落地的挑战。其中,应用发展较快的为传统产业赋能和金融领域。

金融业的痛点在于,其IT架构庞大,数据量很高,如何在符合数据安全合规等要求下,用大模型的能力实现降本增效,并扩展其兼容能力。
再加上金融行业对信息准确性、数据合规等要求较高,短期内,大模型在金融行业的落地方向集中于研报撰写、客服辅助提示等非核心系统应用。从长期来看,大模型的应用方向在金融领域将进一步扩大,随着大模型能力的进一步提升,招股书生成编写、智能研报合规审查、大模型智能数据治理等场景或许将与大模型实现更好的结合。
目前,基于大模型技术,AI独角兽公司旷视科技推出个人征信创新技术方案,该方案可以自动筛选有效变量,并通过Transformer架构进行自监督预训练,进一步预测用户的贷款意愿。在此基础上,旷视科技与朴道征信合作打造的个人客户资质评分服务,帮助朴道征信的客户转化率提升了20%。
传统产业是我国经济的重要组成部分,大模型技术在推动传统产业的数字化转型升级方面扮演着重要角色。
这一产业的特点在于,中小企业在营销工具、IT研发等方面基础薄弱,平台型企业较难带动产业链上中下游中小企业,以及因传统企业涉及场景较多,其市场需求个性化程度较高,中小企业很难快速了解企业的核心痛点。
因此,《白皮书》提到,针对传统产业的痛点,一些头部玩家可以建立专属企业的大模型,加速构建新一代人工智能能力基础设施,然后构建不同的大模型应用。中小企业可以从试点场景出发,找到大模型落地应用的真实价值后,再进行广泛应用。
正如此前提到的,智能客服等场景对于大模型价值的体现更为快速且直接,因此传统产业在验证大模型市场价值初期,也可以从这一场景切入。
以国家电网为例,其在大规模复杂电网系统管理运营方面面临电网设备数量多、关键设备运行缺陷需快速发现响应。结合文心大模型,百度打造了电网智能分析与智能应用平台,并训练了电力行业NLP大模型,在电力专业分词任务上,F1(精确率和召回率的调和平均数)指标达到92.376%。
值得注意的是,大模型在加速各行各业转型升级、降本增效的同时,这些典型案例也体现出目前国内大模型在应用落地方面仍面临诸多挑战,如算力资源持续供应、高质量数据、大模型“幻觉”问题、“蹭热度”以及同质化等。
三、打造公共算力平台、中文互联网语料库,抢滩大模型应用
大模型发展与算力、算法、数据密切相关。其中,训练数据的数量、质量等是大模型智能水平的关键因素。
北京智源人工智能研究院副院长兼总工程师林咏华谈道,目前大型语言模型、多模态大模型中使用的开源数据集多来自海外,中文部分较少,如Common Crawl中中文数据占比不到5%,且其中超80%为海外网站,因此这些数据在训练大模型时会有英文思维,并且存在内容安全风险。

在大会的“大模型创新论坛”上,北京智源人工智能研究院发布了“中文互联网语料库(CCI)”。该语料库是在中国网络空间安全协会人工智能安全治理专业委员会数据集工作组、北京市委网信办、北京市科委中关村管委会、海淀区政府的指导下,由智源研究院联合拓尔思、中科闻歌共建,旨在为国内大数据及人工智能行业提供一个安全、可靠的语料资源,并以此为契机促进不同机构合作,共同推动大数据和人工智能领域的健康发展。
该语料库首期开放的数据(CCI v1.0.0)规模为104GB,数据集总体的时间跨度为2001年1月至2023年11月。

目前CCI语料库首期开放的104GB数据,包括智源研究院400GB“悟道”数据集、拓尔思贡献的250GB数据集、中科闻歌贡献的200GB数据集。
为了保证数据质量,智源研究院会对上述数据基于合规站源数据进行高质量数据清洗、去重,同时为了避免数据集混杂测试数据,他们会把可能存在的主流评测数据进行过滤。

从今年4月到10月,国家网信办发布的《生成式人工智能服务管理办法(征求意见稿)》、以及国家网信等七部门联合发布的《生成式人工智能服务管理暂行办法》等都强调了数据真实、安全等。
今年10月,中国网络空间安全协会设立了人工智能安全治理专业委员会,下设数据工作组,其目的在于联手国内数据、互联网、大模型等企业,推动中文语料库的建设。
林咏华谈道,构建高质量的中文语料库主要有三个阶段,首先是建设中文互联网语料库,这是一个长期持续的过程,本次发布的中文互联网语料库,其数据主要来源为地市级以上政府门户网站、重点新闻网站、中央和地方报刊等。
第二个阶段就是建设综合数据集,其囊括的数据范围也更加广泛,包括科技类、媒体类、书籍期刊等文字、图片、视频等数据。
第三个阶段就是建设行业数据集,针对不同行业的应用需求,打造面向金融、医疗等领域的数据集。

为推动“中文互联网语料库CCI”的广泛使用,吸引国内大模型领域研究机构、企业共建、共享高质量、多样化、安全合规的中文语料库,会上,智源研究院联合17家大模型机构和企业共同发起《“中文互联网语料库”共建共享倡议书》,倡导坚持合作共享、安全合规、数据高质量等6项原则,持续推动人工智能产业健康持续发展。
在商业落地背后,算力基础设施是支撑人工智能产业发展的坚实底座。北京市海淀区的北京人工智能公共算力平台举行了点亮仪式,同时,北京电信作为算力平台代表与智谱华章、紫东太初等首批入驻大模型企业完成了签约仪式。

结语:开启大模型应用落地新阶段
如今,大模型的技术创新升级与商业落地正稳步推进,作为国内在大模型领域具有一定资源优势、先发优势的城市,北京市已经锚定大模型下一阶段发展的核心及持续性痛点,通过算力基础设施、中文互联网语料库、应用创新等,为国内大模型产业发展筑起坚实的底座。
《白皮书》提到,北京市将进一步培育大模型产业生态,将人才、资金、产业生态等方面与大模型产业发展结合的更为紧密;在算力方面,北京市也通过算力券、资金补贴等为企业提供支撑;在行业落地角度,北京市还通过行业大模型创新应用大赛,为企业探索大模型实际落地场景提供机会;同时,在大模型应用监管方面,北京市也提供了围绕大模型底层设施、关键技术、上层应用的标准体系。
大模型产业发展至今,企业对于大规模商业落地的探索加快,可以看出,北京市已经形成了从算力、数据、应用三个角度出发,围绕软硬件基础设施、关键技术、应用落地等重点为这一产业打造了一系列支撑,大模型正重塑千行百业。
https://zhidx.com/p/405280.html
More articles on Future Tech
ByteDance seeks US$1.1mil damages from intern in AI breach case, report says
Created by Tan KW | Nov 29, 2024
India competition watchdog to investigate Google's gaming app policy
Created by Tan KW | Nov 29, 2024
Microsoft informed of yet another antitrust probe by US authorities
Created by Tan KW | Nov 29, 2024
China starts building world's largest fully steerable radio telescope
Created by Tan KW | Nov 29, 2024
The only thing worse than being fired is scammers fooling you into thinking you're fired
Created by Tan KW | Nov 29, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts



Latest Videos





Apps


Top Articles
1
2
save malaysia!
3
PublicInvest Research
4
M+ Online Research Articles
5
Good Articles to Share
The 'Fast Money' traders share the stocks they are thankful for this holiday season
6
Good Articles to Share
Australia passes social media ban for children under 16 | REUTERS
7
Good Articles to Share
8
Good Articles to Share
Storms to ruin travel in U.S. over Thanksgiving weekend: reports
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....