





Future Tech
[转贴] 谷歌7大模型22项AI大招轰炸!70秒视频生成、Gemini安卓合体、200万tokens上下文

智东西(公众号:zhidxcom)
作者 | 智东西编辑部
智东西5月15日报道,今日凌晨,在一年一度的谷歌I/O开发者大会上,谷歌干了一场AI硬仗!
时长不到2小时的开幕式期间,谷歌CEO桑达尔·皮查伊携一众谷歌高管总共提到121次“AI”。谷歌DeepMind的联合创始人兼CEO戴密斯·哈萨比斯首次在I/O大会上发表演讲,顺序仅次于皮查伊,足见AI大模型已经成谷歌的头等大事。

在昨天OpenAI发动奇袭、推出干掉传统语音助手的旗舰模型GPT-4o后,作为“全球AI一哥+搜索一哥”的谷歌,势必得扳回一城,搏一搏谁才是AI赛道的头号“大模王”。
这次,谷歌连珠炮般甩出了22项AI大招,包括公布200万tokens超长上下文Gemini 1.5 Pro进阶版、Gemini 1.5 Flash轻量级模型、通用AI Agent、高质量文生图模型Imagen 3、AI音乐创作工具Music AI Sandbox、70秒视频生成模型Veo、首个视觉语言开放模型PaliGemma等多款模型,还剧透了下一代Gemma 2大模型。
Veo生成视频的部分片段:

其他大招包括第六代TPU、AI基础设施、AI搜索新功能、Google Workspace应用Gemini功能、Gemini Live多模态功能、Gemini定制功能、Gemini Advanced、画圈即搜功能、Gemini Nano新功能、安卓Gemini合体、AI辅助红队技术、扩展和开源SynthID文本水印等。
谷歌还展示了一系列AI系统,包括将视觉和语言转化为机器人行动的RT-2、浏览复杂虚拟3D环境的SIMA、解决奥数问题的AlphaGeometry。
发布会开场,皮查伊称目前有超150万开发人员在使用Gemini模型,谷歌拥有20亿用户的产品都在使用Gemini,谷歌推出安卓和iOS上可用的应用程序直接与Gemini互动,3个月内已有超过100万人注册尝试。
谷歌今天的诸多AI大招还有哪些精彩细节,这些技术又将如何深度影响产业,我们将带你一文看尽。

一、未来通用AI Agent:日常生活随时答疑解惑的超级助手
昨天OpenAI果然是有预谋的精准狙击,率先亮出聊天丝滑宛如真人、具有炫酷实时视频理解能力的旗舰模型GPT-4o,导致今天谷歌展示的未来AI助手Project Astra演示有点儿眼熟:
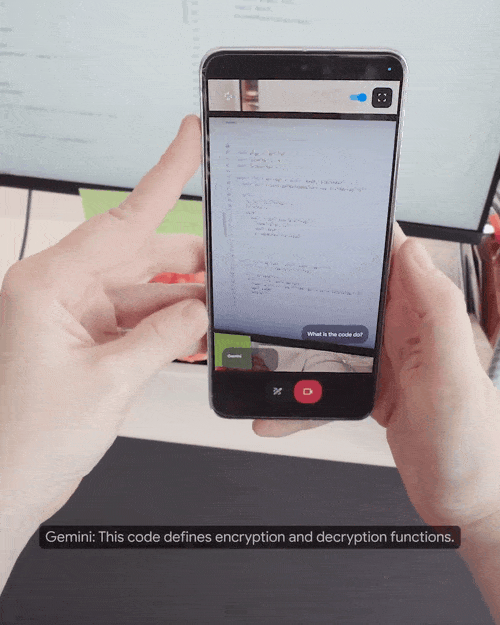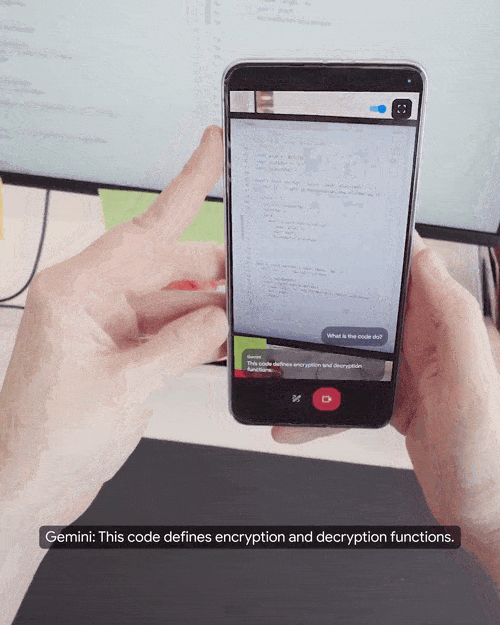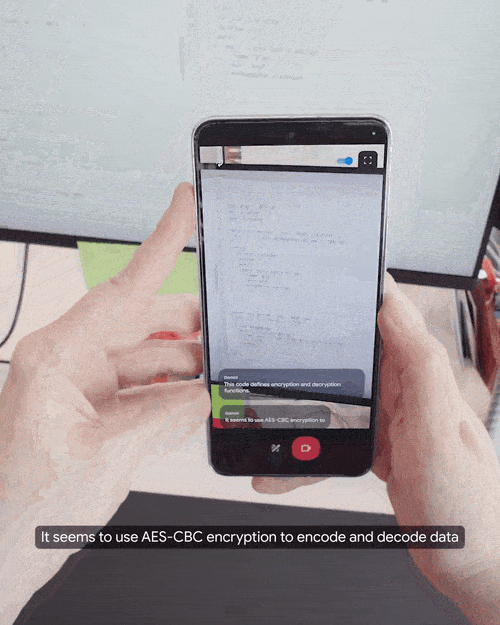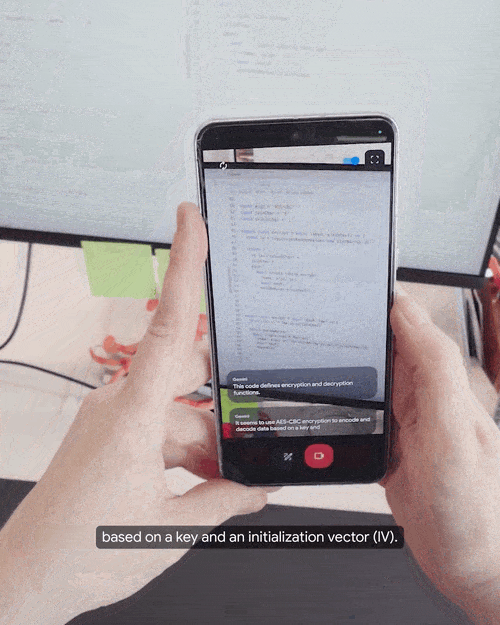
演示者打开手机摄像头,边走边问摄像头捕捉到的现实场景中的问题。
比如要求“看到能发出声音的东西就告诉我”,Gemini就会给出准确描述:“我看到一个音响发出声音。”接着你可以在手机屏幕上画出红色箭头,追问“音响的这部分叫什么”,Gemini立即回复说这是“高频扬声器”并解释它的用途。
再比如要求Gemini给出创造性的头韵体,它随即根据画面中的蜡笔给出回答:“Creative crayons color cheerfully. They certainly craft colorful creations.”
实时解答代码同样不在话下。
甚至扫一眼周围环境,Gemini就能推断出你住在哪个小区。
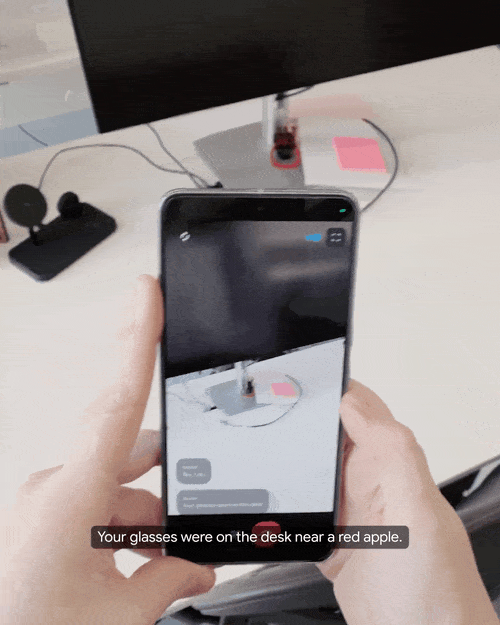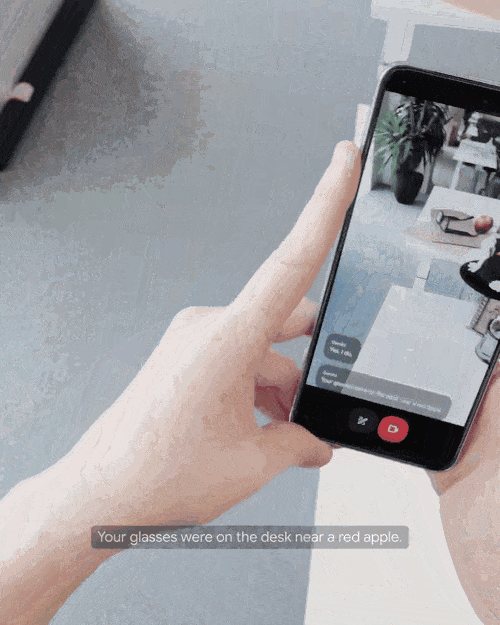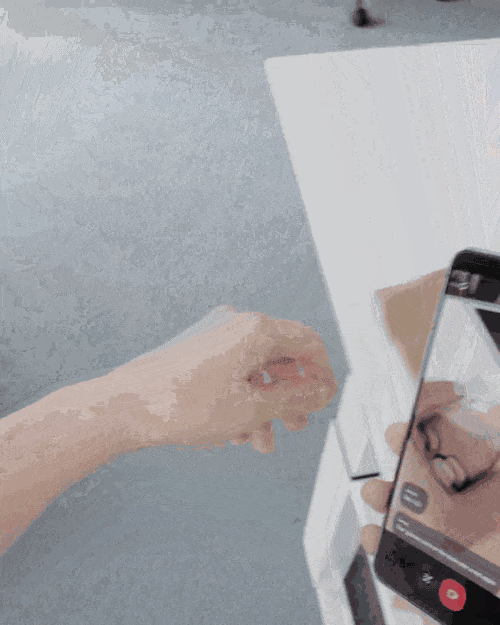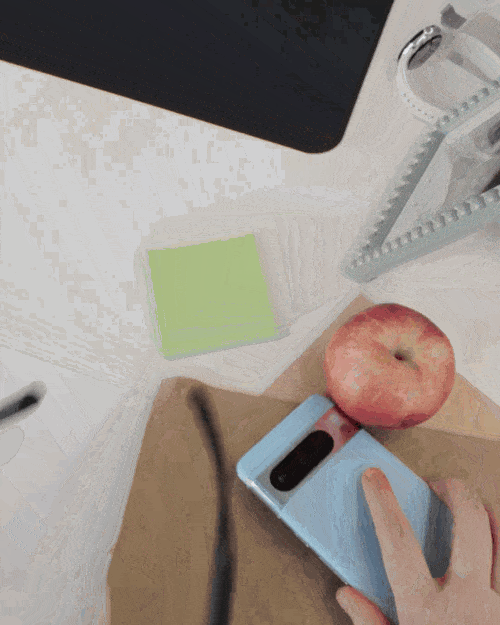
找不到东西也可以请求Gemini的帮助,问问它有没有看见自己的眼镜在哪儿,Gemini立即发现它在桌面上靠近一个红苹果的地方。
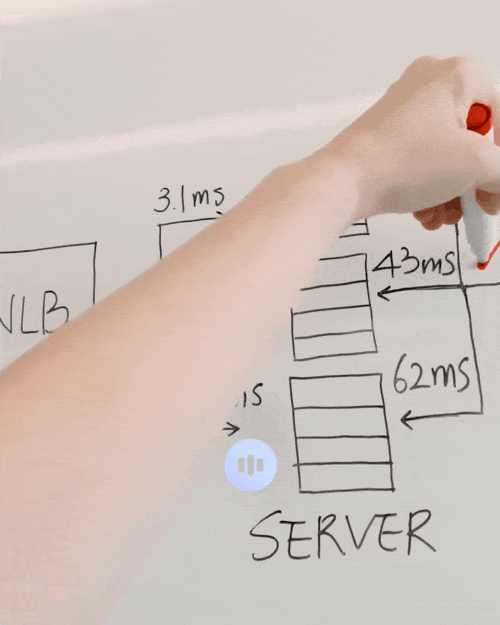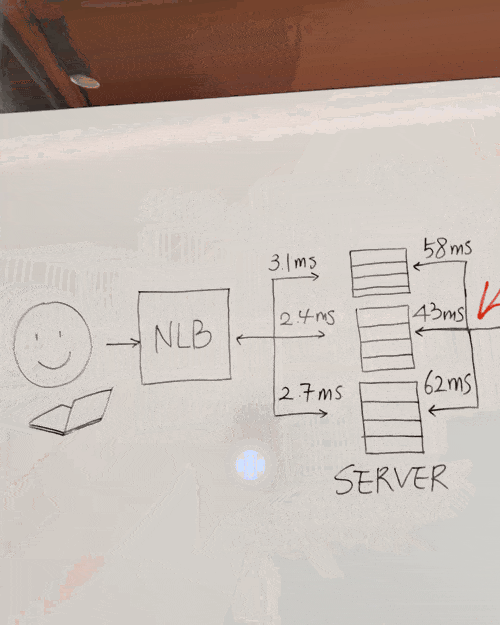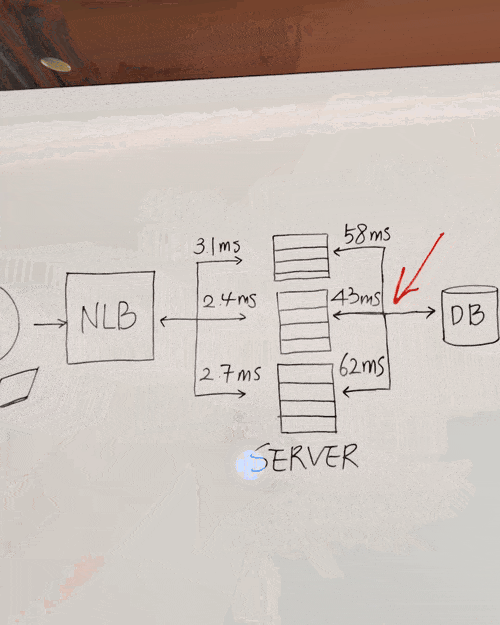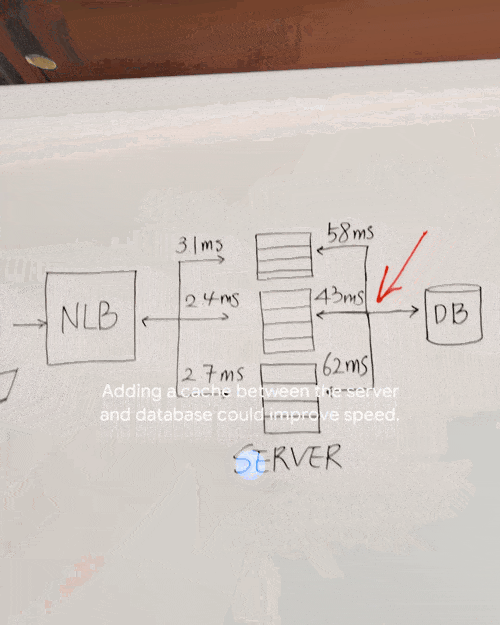
你还能直接现场板书,问在这里可以添加什么来使得系统更快,Gemini回复说“在服务器和数据库之间添加缓存可以提高速度”。
此外,问它看到这个画面能想起什么,Gemini能瞬间理解它指的是“薛定谔的猫”。
让它给小狗和老虎玩偶的组合起个乐队名,Gemini给出的建议是“金色条纹”。
1、Veo:全新视频生成模型,只需一个文本、图像或视频提示,就能制作和编辑70秒以上不同视觉风格的高质量1080p视频。
OpenAI发布Sora后,视频大模型的热度就一直居高不下,今天谷歌的Veo也算是正面硬刚Sora了。
用户可以自定义各种风格模式,还能通过点击增长时间,视频时长可以超过1分钟。
从Veo生成的视频中我们可以看到,AI对空间中的物体关系是有理解的。比如车辆是如何在道路上行驶的,车辆之间的位置关系等等。
同时,Veo生成的视频镜头有不错的一致性,人、动物、物体的移动显得比较真实、自然。
谷歌说,Veo是他们在视频生成领域技术的集大成制作,包含了多年来谷歌开发的生成查询网络(GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet和Lumiere等各类技术。
值得一提的是,Veo还能理解很多电影术语,比如“时光倒流(Timelapse)”。
在演示视频中,电影导演也用到了Veo,Veo帮他们把灵感变成现实,电影导演说,AI可以帮他们快速发现构思中的错误并快速纠正,提高效率。
谷歌称,实现这些,需要让AI模拟世界的物理法则,这是很关键的。
用户可加入实验室等待名单,在新实验工具VideoFX中尝试。
2、Imagen 3:谷歌迄今最高质量的文生图模型,能更好理解文本,创造出逼真图像,能从草图快速生成高分辨率图像。谷歌自信地说Imagen 3是目前最强大的图像生成模型。
Imagen 3生成的图像可以达到“数毛”级别,具备非常多的画面细节,同时其光影细节也非常震撼。
Imagen 3可以像人一样理解世界,可以理解文字中的信息对应图像中的哪一部分,并且具备上下文理解能力。
Imagen 3可以更好地理解自然语言,理解提示文字背后的意图,比如它可以理解人物照片中的背景虚化效果、人物跟背景中植物和建筑的关系。
3、Music AI Sandbox:AI音乐创作工具,可以改变音乐的创作方式,谷歌与音乐家、词曲作者和制作人密切合作来帮助设计和测试这款工具。
在生成式音乐创作方面,谷歌通过Music AI Sandbox跟音乐家合作,音乐家可以直接把一段哼唱或者弹奏的灵感片段发给AI,生成一首歌或者一段真正的旋律。
音乐家说,AI就像一个朋友,让你试试这个、试试那个,这可以解放他们的创造力,让他们更高效地创作音乐。
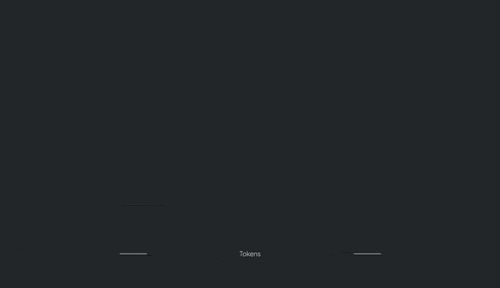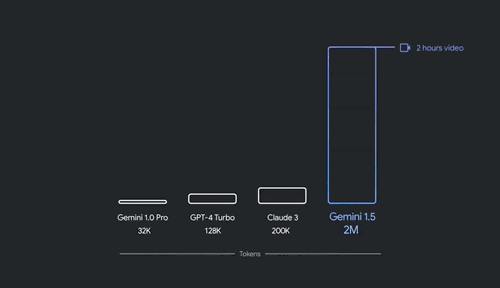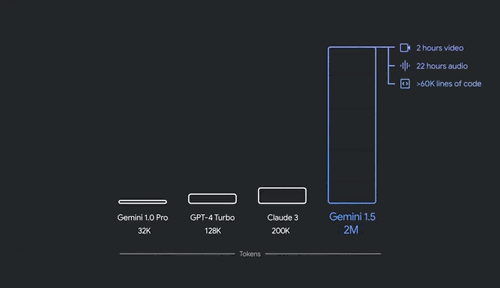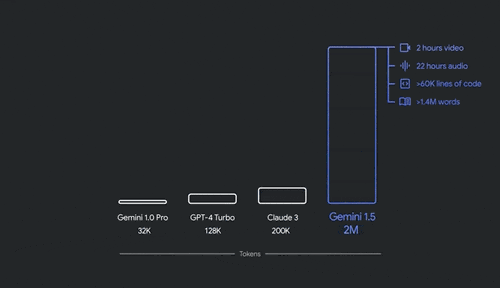
4、Gemini 1.5 Pro进阶版:多模态,上下文窗口扩展至200万个token,改进代码生成、逻辑推理和规划、多轮对话、音频与图像理解能力,支持35种语言,面向全球开放。
上下文扩展到200万个tokens,意味着它能够处理1500页PDF、30000行代码或是1小时的视频。Gemini 1.5 Pro在翻译、编码、推理等方面,可处理更广泛、更复杂的任务。
皮查伊宣布把Gemini 1.5 Pro的进阶版开放给全球开发者使用。
Gemini 1.5 Pro即日起面向谷歌Workspace Labs进行开放,支持用户在工作场景中获得更多智能功能。
皮查伊谈道,多模态+上下文可以解锁不少新功能。比如基于Gemini在谷歌Gmail邮箱中搜索内容,人们可以问Gemini“小朋友最近在学校做什么?”,Gemini就会去识别相关邮件及附件,给出一个关键要点的列表。
现场谷歌演示了NotebookLM的音频概述功能,用户只需将文本资料输入进去,该软件即可基于Gemini Pro 1.5能力,生成丰富的音频内容素材,就像整合成一个课本一样,互动性、沉浸性较高。
5、Gemini 1.5 Flash:轻量级模型,针对低延迟和低成本任务(聊天应用、从长文档提取数据等)进行了优化,成本效益更高,上下文窗口达100万个token。
Gemini 1.5 Flash模型,相比此前的Gemini 1.5 Pro,该模型的特点是轻量级,支持快速、多模态、长上下文的推理。
价格方面,Gemini 1.5 Pro为7美元/100万tokens,对于128k以下的输入,将降价50%至3.5美元/100万tokens;Gemini 1.5 Flash的价格为0.35美元/100万tokens。
Gemini 1.5 Pro和Gemini 1.5 Flash这两款型号的模型现已在200多个国家和地区提供预览版,并将于6月全面上市。
6、PaliGemma:谷歌首个视觉语言开放模型,Gemma系列型号在轻量级7B和2B尺寸方面将提供行业领先的性能。
谷歌此前于2月推出开源模型Gemma,包含7B、2B两种参数规模,在各大开源社区下载量已累计数百万次。
今天,谷歌发布其首个视觉语言开放模型PaliGemma,基于SigLIP视觉模型和Gemma语言模型等开放组件构建,用于在各种视觉语言任务上实现一流的微调性能,包括图像和短视频字幕、视觉问答、理解图像中的文本、对象检测和对象分割等。
7、Gemma 2抢先看:将在未来几周正式发布一个有270亿个参数的模型版本。Gemma 2 27B性能媲美Llama 3 70B,尺寸不到Llama 3 70B的一半,可在NVIDIA GPUs或Vertex AI单个TPU主机上运行。
Gemma 2还在进行预训练。下图展示了最新的Gemma 2检查点的性能以及基准预训练指标。
8、LearnLM:基于Gemini的新系列模型,对学习进行了微调,应用教育研究使谷歌搜索、Gemini、YouTube等产品更加个性化、更活跃、更吸引学习者,将在未来几个月发布。
1、AI搜索:到今年年底,谷歌搜索的AI概览将超过10亿人。谷歌搜索将很快推出多轮推理能力,可将复杂问题分解处理,将原本需要几分钟甚至几个小时的研究压缩到在几秒钟内完成,还将支持在搜索中对视频提问。
皮查伊宣布,谷歌即日起开始向每位美国用户推出基于Gemini改进的搜索体验,本周将向更多国家开放。
在谷歌照片方面,Gemini让照片搜索变得更容易。假设用户在停车场准备付款但想不起自己的车牌号,他可以简单地询问Gemini,基于之前拍的照片告诉用户车牌号码。
基于此谷歌宣布推出AI Overviews工具,将陆续面向美国及各国用户开放。
谷歌AI Overviews功能相比传统搜索引擎的结果,其将为用户呈现出完整的包括观点、见解、链接的答案。
谷歌搜索负责人Liz Reid强调,谷歌的AI搜索概述有三大独特优势:实时信息、排名和质量体系、Gemini模型能力。
今天起,谷歌AI搜索概述将在美国全面推出,后续推广到更多国家和地区,在今年内覆盖10亿用户。
Reid称,谷歌引入多步推理功能(Multi-step reasoning),把大问题分解为小部分,并判断优先顺序。
例如,用户想找一个合适的普拉提工作室,需要同时考虑时间、价格、距离等因素。用户可以在谷歌搜索输入:在波士顿找到最好的瑜伽工作室,并显示优惠详情、从我家过去的步行时间。
谷歌搜索将提炼整合出这些信息,并呈现在AI搜索概述中,为用户节省数个小时的时间。这一功能也适合用在出行、聚会等规划上,或是餐饮计划的定制等。
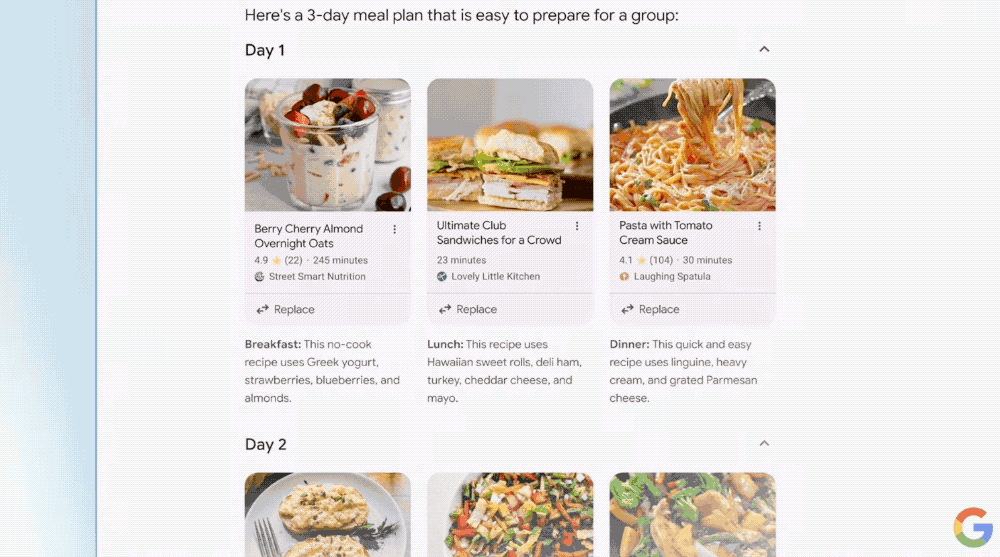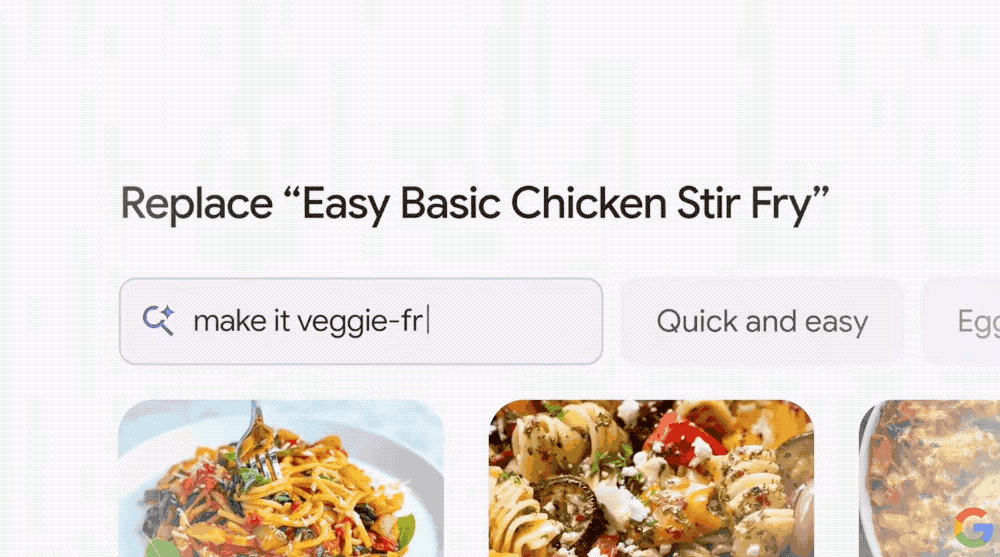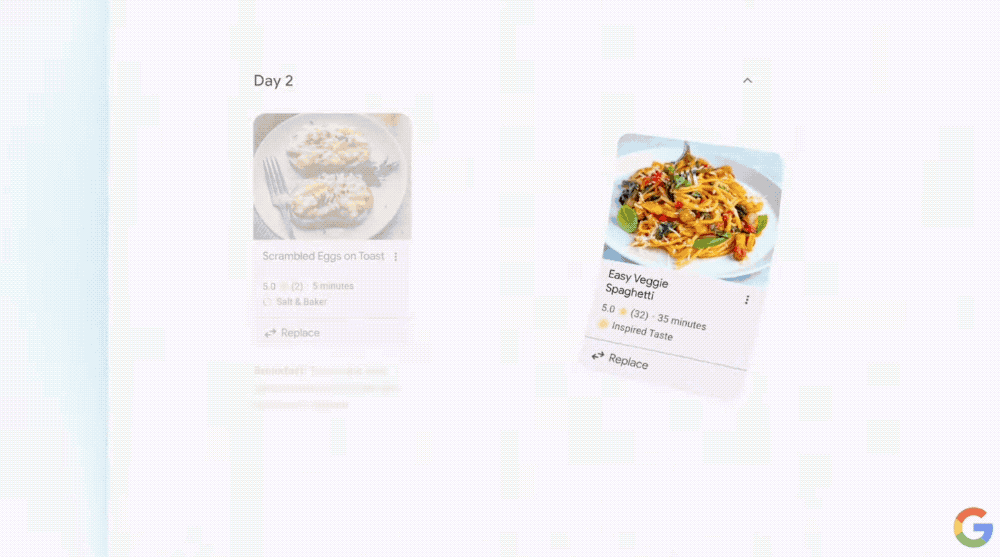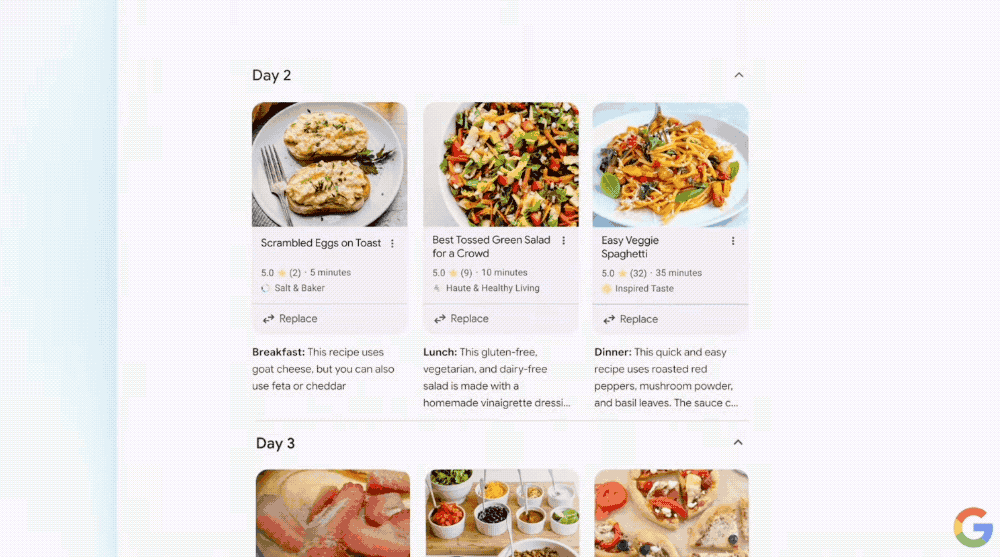
例如“为团队定制一个三天的餐饮计划”,AI搜索概述不仅能提供各类型的食谱,还能直接将食谱中用到的食材等导出成购物清单,这意味着用户仅需提问,就能将所需的一切加入购物车。
此外,谷歌搜索还将很快推出视频搜索功能。例如可以通过拍摄电唱机,来获取故障排除相关的AI搜索概述。
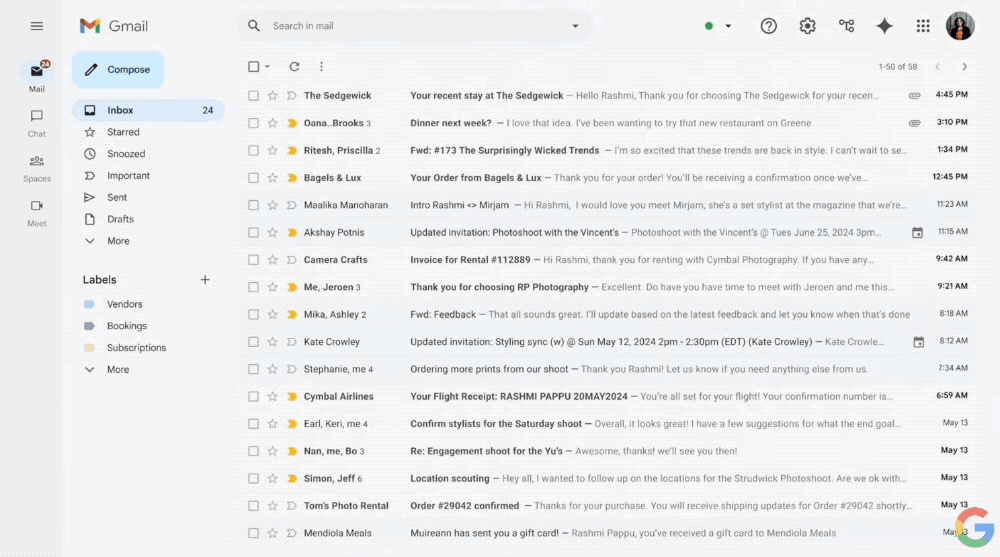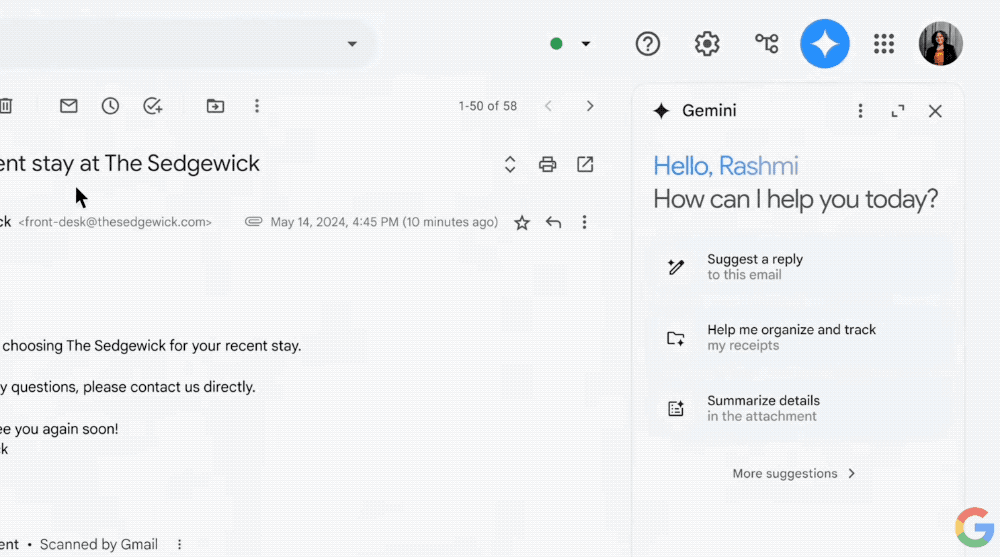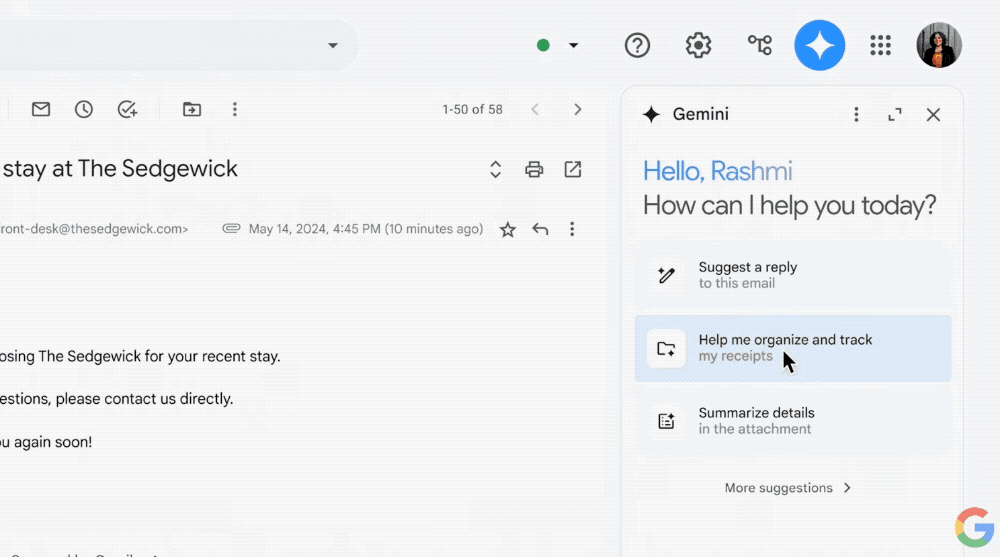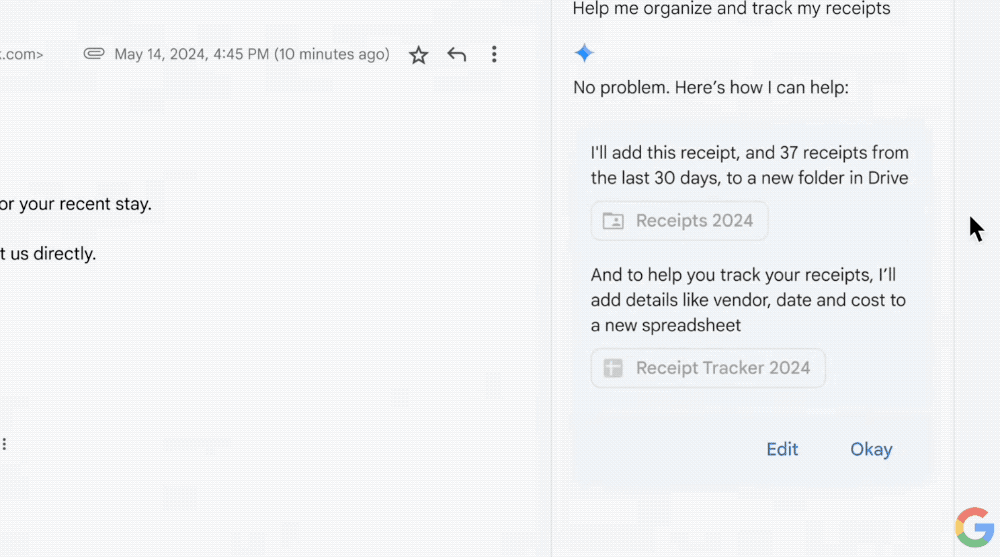
2、Google Workspace应用:侧边面板可使用Gemini 1.5 Pro模型,将使跨应用程序的工作变得更加容易,例如在Gmail中识别收据并在Drive和Sheets中组织收据,还可以通过数据问答让Gemini帮你分析开支。
AI在我们的日常办公中能有什么妙用,这次谷歌在Workspace中增加了不少AI重磅新功能。
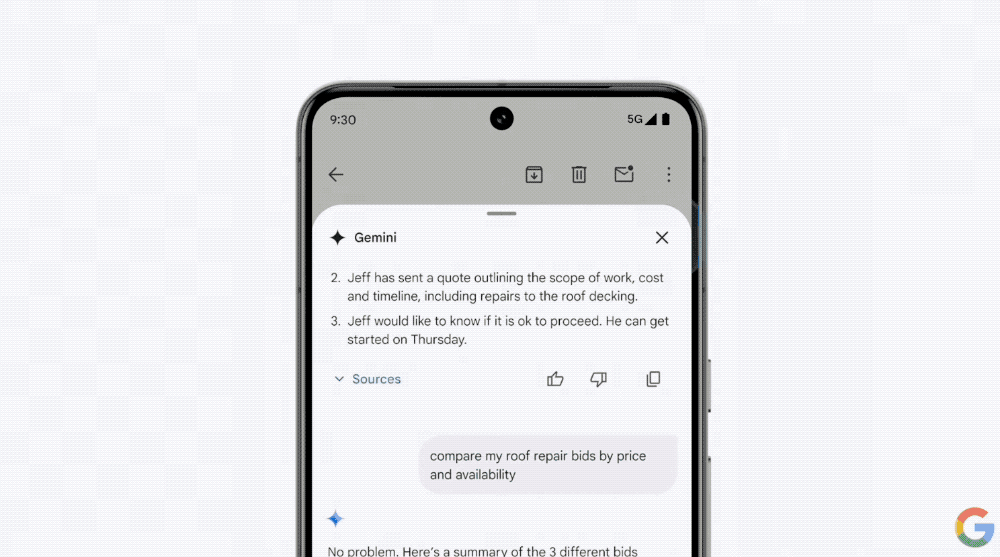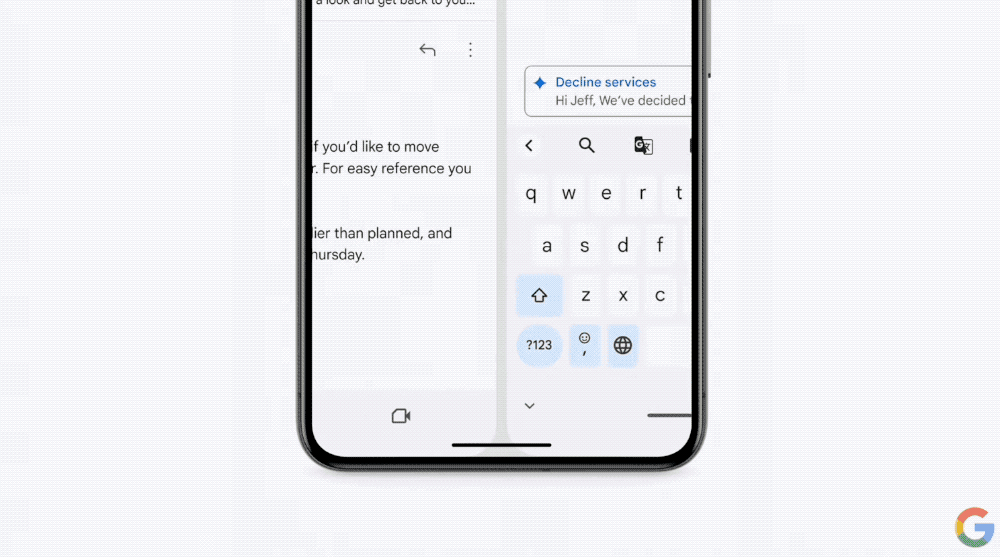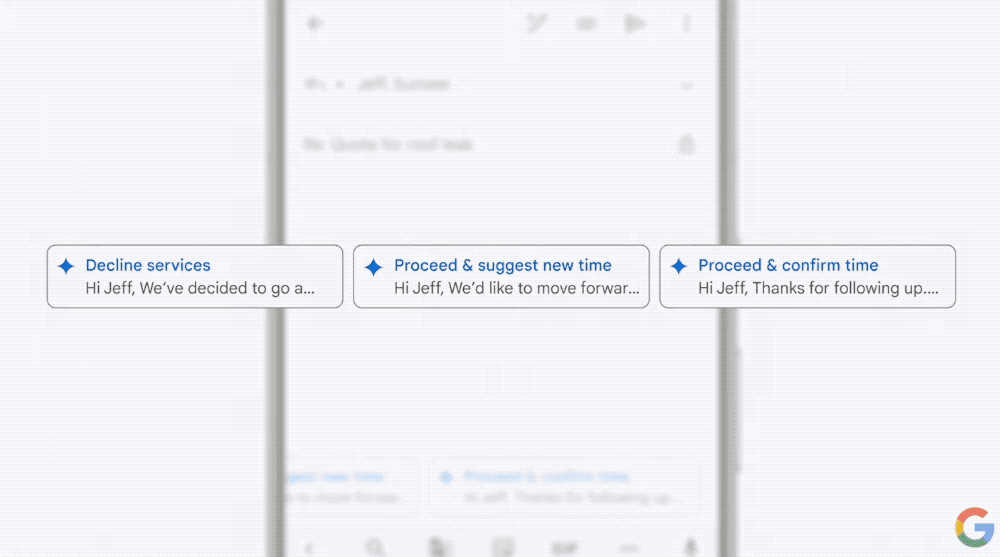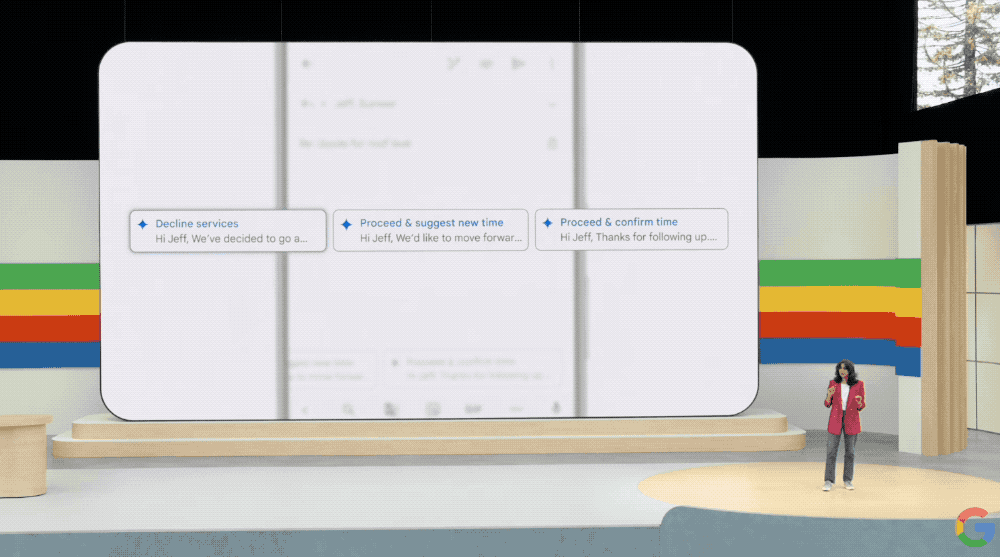
在邮件应用中,Gemini可以根据我们的需求总结邮件中的信息,比如家里屋顶漏水了,Gemini可以帮你找到所有修复屋顶的公司发给你的邮件,按照各个公司的报价、可以服务的时间进对比。
Gemini可以找到价格相对合适,上门服务时间最快的合同商,我们确定后,Gemini还可以提供邮件回复建议。
值得一提的是,Gemini是有理解语境能力的,AI知道之前的邮件中都说了什么。
更进一步,在邮件应用中,Gemini还可以帮你追踪所有订单、相关收据,把这些邮件进行归纳整理,放到一个文件夹里,然后把其中关键信息整理进表格里。
用户可以直接选择自动化工作流,后面所有相关订单邮件都会放到文件夹里,关键信息也会自动整理进表格。
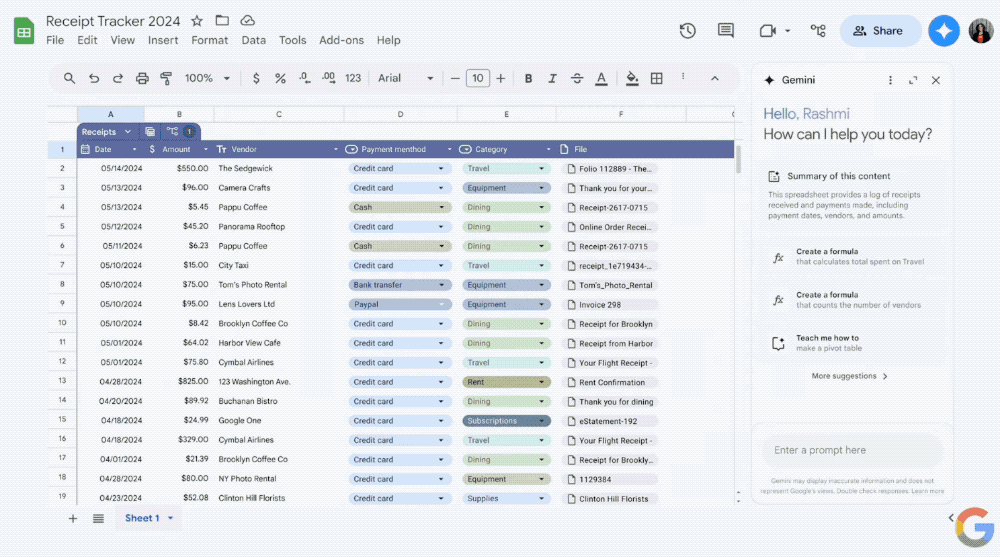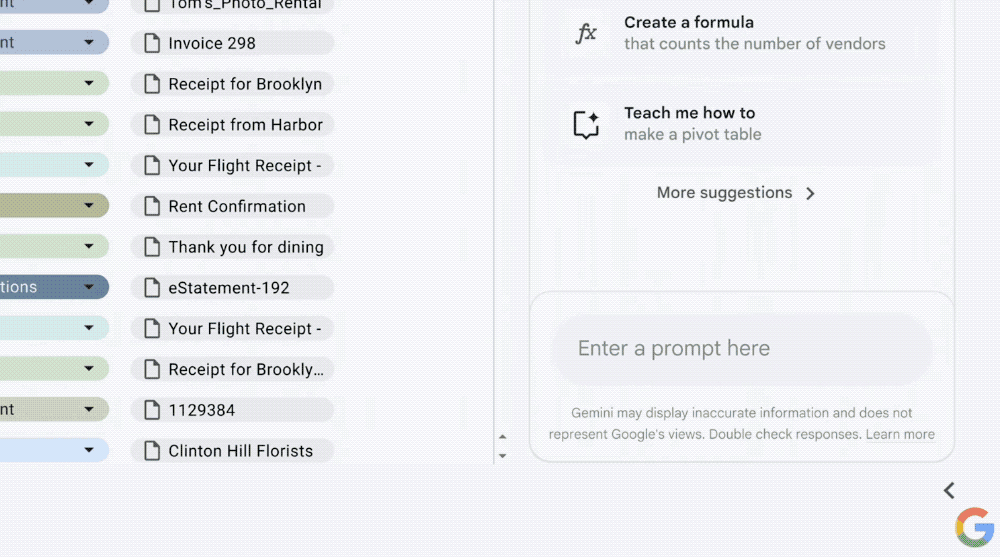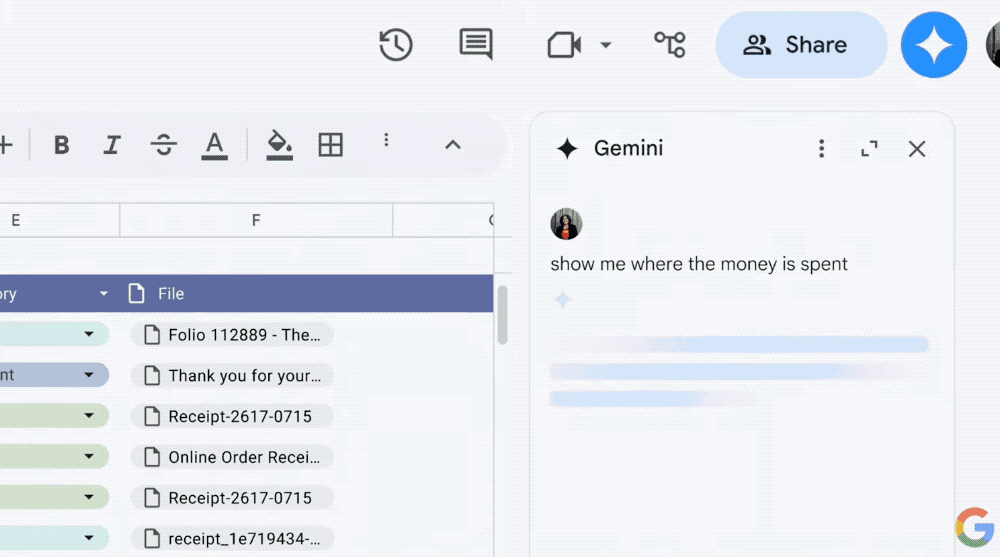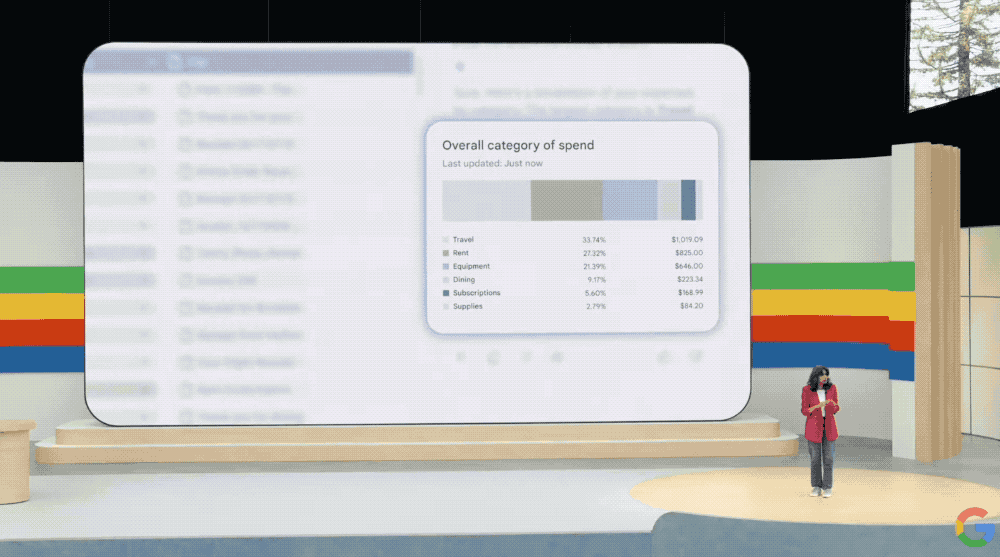
我们还可以直接问Gemini“我的钱都花在哪里了?”Gemini可以直接用图表给你展示出来,让你清清楚楚地知道自己哪里花销最大。
此外,在公司办公协作场景中,谷歌还推出了一个“AI虚拟员工”功能,可以说是打造了一个“最强AI实习生”。
这个AI虚拟员工会有一个Workspace账号,用户可以对其自由命名、指派任务。
▲右侧为用户建立的AI虚拟员工Chip
我们可以把这个AI虚拟员工放在各个工作群组里,它可以在各个群聊中提取信息,找到关键信息。
值得一提的是,这个AI员工可以有“集体记忆”,可以总结之前的一些工作重点,还可以把总结发送给相关人员。谷歌高管称,以前需要几个小时做的,现在AI几分钟的就可以做好。
可以说,这着实是最强AI企业实习生了。
3、Gemini Live:今年夏季将扩展Gemini的多模态功能,包括使用你的声音进行深入的双向对话的能力。
在Gemini APP中,谷歌推出Gemini Live功能,用户可通过文本、语音或影像多种方式进行交互,直接与大模型进行对话,并能够随时打断,可以打开摄像头使其“看到”周围的世界并实时响应。
Gemini Live将在未来几个月内,优先向Gemini Advanced订阅用户推出。
4、Gems:Gemini定制功能,无论你需要一位瑜伽闺蜜还是微积分导师,都可以定制专属的Gemini来以特定方式进行互动。
用户可以通过简单的指令打造个人专家,例如写作教练、瑜伽老师、代码检查器等。在构建过程中,用户可直接选择Google Drive中的文件上传。
Gemini还将连接更多谷歌工具,包括日历、任务、邮件等,在这些应用中用户能够通过简单的提示获取AI体验。
5、Gemini Advanced:今年夏季将新增旅行计划功能,支持创建个性化的行程;即日起支持访问Gemini 1.5 Pro,具有100万个tokens上下文窗口,可上传多达1500页的文件;接下来几周内新增数据分析功能,上传电子表格即可更快分析数据、制作图表、发现见解。
6、画圈即搜功能:在你的手机或平板电脑上圈出复杂的物理问题,就能获得一步一步的指导,学习如何解决问题。
AI搜索方面,画圈即搜功能大家已经在三星的手机上看过了,比如画圈找心仪的商品信息。
今天谷歌给画圈即搜增加了新能力,在学习过程中,用户可以直接把不懂的问题圈出来,Gemini就会给用户一步步的问题解答,可以说摇身一变成为最强辅导老师——谷歌圈读机,哪里不会圈哪里。
谷歌称,画圈即搜后续面可以处理公式、复杂图表,目前已经应用在1亿台设备上,谷歌计划把这个数字在年底翻倍。
7、安卓版Gemini新功能:推出Gemini app,安卓系统上的Gemini变得更有帮助,更有环境意识;今年晚些时候支持将生成的图像拖放到Google Messages和Gmail中,还支持用户直接在设备上询问有关YouTube视频和PDF文件的问题。
谷歌要怎么做手机上的AI,今天答案有了:谷歌要做“系统级AI”,把Gemini用在安卓系统底层。这对于产业的重要意义不言而喻,所有安卓手机,可能都会享受到这一“AI福利”。
谷歌说,他们要让安卓成为体验谷歌AI的最强移动平台。
对于“系统级AI”,谷歌进行了重点解读。谷歌希望让Gemini成为安卓体验的基础。
所以区别在哪?Gemini在系统级层面运行,因此用户不需要打开应用。同时Gemini有了上下文感知能力,它知道你在干什么,可以成为更有用的助手。
比如,Gemini可以帮用户在聊天中生成有趣的表情包图片,Gemini可以感知到用户在看视频,弹出提示,询问是不是想了解关于这个视频的问题,用户可以直接询问视频中的细节,Gemini可以直接从视频中找到答案。
比如当朋友发过来一个关于匹克球规则的84页的PDF,Gemini会检测到,并询问你是不是要了解这个PDF,你可以把PDF直接甩给Gemini,它就会成为一个匹克球的“运动专家”,用户问什么规则,它都可以解答。
这种系统级AI具备上下文感知能力,可以提供更即的时帮助。谷歌特别强调说,这些体验只在安卓上可以用——Only on Android。
这下,压力给到了苹果。
谷歌把AI直接嵌入到了操作系统中,称这是首个内置端侧AI的移动操作系统。
谷歌预告称,今年晚些时候,Gemini Nano的功能会在Pixel系列手机上落地。
对于视障人士,TalkBack读屏功能,此次升级了多模态能力,可以更加清晰的描述一张图片,比如服装的款式,这些功能都是端侧实现的,不需要联网。
谷歌还发布了端侧AI的另一个应用,预防电话诈骗。手机发现用户接打有风险的陌生的来电时,会直接发出警告,告诉用户这个电话可能是个诈骗电话。
所以谷歌要做什么,谷歌要做的就是以Gemini为核心的安卓。
这些功能会在安卓15 Beta 2版本中落地。
8、Gemini Nano新功能:多模态功能很快将上线,使手机可以通过文本、视觉、声音和口语来理解世界;今年晚些时候安卓辅助功能TalkBack将在Gemini Nano上得到提升,图像描述将更清晰、更丰富,帮助低视力和盲人用户通过语音反馈更好地导航他们的手机;安卓一旦检测到可疑活动,就会在通话过程中发出警告,比如被要求提供社会安全号码和银行信息。
1、第六代TPU:谷歌迄今性能最高、最节能的TPU,相比上一代TPU v5e,每颗芯片的峰值计算性能提高了4.7倍,节能67%以上,HBM容量和带宽提高1倍,Interchip Interconnect带宽提高1倍,可在单个高带宽、低延迟POD中扩展到256个TPU,还配备了专门用于处理高级排名和推荐工作负载中常见的超大型嵌入的专用加速器第三代SparseCore。
Trillium配备的第三代SparseCore加速器,可以更快地训练基础模型,并提供更低的延迟和成本。
Trillium在单个高带宽、低延迟pod中可扩展至256个TPU,利用Multislice技术和Titanium 智能处理单元(IPU),Trillium还可以扩展到数百个pod,通过每秒数万比特的数据中心网络互联,将数万个芯片连接到楼宇级超级计算机中。
第六代TPU Trillium将于今年晚些时候上市,此外Pichai还透露,谷歌将与英伟达合作,在2025年推出Blackwell平台。
2、AI基础设施:从AI超算到跨越200多英里陆地和海底光纤的海底电缆网络,谷歌持续投资推进AI创新,投资世界一流的基础设施。
3、AI辅助红队:使用谷歌DeepMind的AlphaGo开发的一种新技术,训练agents相互竞争,提高红队能力,这有助于对抗提示并限制有问题的输出。
4、扩展SynthID水印功能:谷歌去年推出的SynthID为AI生成的图像和音频添加了难以察觉的水印,使它们更易区分,今天谷歌将SynthID扩展到Gemini应用和web体验中的文本输出,并在全新视频生成模型Veo中对视频进行水印。接下来几个月里还将开源用于文本水印的SynthID。
▲用于视频水印的SynthID标记生成的视频的每一帧
5、扩展负责任的生成式AI工具包:通过发布开源的大语言模型比较器(一种新的交互式和可视化工具),帮助开发人员进行更健壮的模型评估,有效并行评估模型质量与安全性。
“谷歌搜索是人类浩瀚好奇心的生成式AI——这是我们搜索领域最激动人心的篇章。”皮查伊在谷歌I/O大会上激情洋溢地说。
在OpenAI ChatGPT点燃生成式AI的热焰时,昔日AI老大哥谷歌因为反应迟钝外加“翻车”事件,沦为了顶尖AI大模型竞赛里的追赶者。随后谷歌重燃AI斗志,不断打磨Gemini大模型,并在本届I/O大会上从“AI军火库”中狂掏武器秀实力。
无论是包括Gemma 2、Gemini 1.5 Flash、Imagen 3、Veo等新模型在内的一系列创新,通过文本、语音、视频、图片等多模态的搜索方式升级,还是为下一代AI模型与agents提供更快、更低延迟训练和服务动力的定制AI专用芯片与基础设施,谷歌披露了这一系列进展,都彰显出巨头雄厚的技术实力和广泛的应用市场。
在激烈的生成式AI竞赛中,OpenAI并非一骑绝尘,最终赢家是谁还有相当多的变数。
https://zhidx.com/p/425208.html





二、8大AI模型/工具炸场!最强文生图、70秒视频生成、200万tokens超长上下文


















三、AI搜索走向多模态!发布最强AI安卓系统,手机上就能圈图提问读文档























四、第六代TPU芯片来了!训练agents提高AI安全




结语:生成式AI落地酣战在即!谷歌用Gemini重塑搜索
More articles on Future Tech
TikTok parent ByteDance’s valuation hits $300 billion amid US ban uncertainty, WSJ reports
Created by Tan KW | Nov 17, 2024
NASA and Microsoft intro Earth Copilot to tame satellite data overload
Created by Tan KW | Nov 16, 2024
What to know about Elon Musk’s contracts with the US federal government
Created by Tan KW | Nov 16, 2024
Netflix down for thousands of users in United States, Downdetector says
Created by Tan KW | Nov 16, 2024
What is DOGE? Houston experts say Trump's new 'department' is not actually a department
Created by Tan KW | Nov 16, 2024
From a US$1mil DoorDash scam to a massive crypto heist, Gen Z linked to sophisticated online crimes
Created by Tan KW | Nov 16, 2024
Bloke behind Helix Bitcoin launderette jailed for three years, hands over $400M
Created by Tan KW | Nov 16, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts
Introducing MY's First IPO Fund for Sophisticated Investors!
New Update. Discover investment communities that resonate with your ideas
M & A Value Partners IPO Equity Fund has been launched - Targeted 13% Return p.a
Latest Videos





Apps


Top Articles
1
2
Mercury Securities Research
3
BFM Podcast
4
BFM Podcast
5
6
BFM Podcast
8
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
No trading signals available.
Stock
Time
Signal
Duration
No trading signals available.
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....