





Future Tech
[转贴] 手机能跑!微软小模型击败Llama 2,96块A100 GPU训练14天,参数规模仅27亿


智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 李水青
智东西12月13日报道,昨日晚间,微软又亮出了小模型大招!
微软发布了27亿参数规模的小语言模型Phi-2,经研究人员测试,Phi-2在参数规模小于130亿的模型中展示了最先进性能。
从性能表现看,Phi-2在Big Bench Hard(BBH)、常识推理、语言理解、数学和编码基准测试中,其平均性能得分已经超过70亿、130亿参数规模的Mistral和Llama 2,在部分基准测试中超过谷歌的Gemini Nano 2。
Phi-2还有一大优势是,因为参数规模足够小,其可以在笔记本电脑、手机等移动设备上运行。
过去几个月间,微软研究院的机器学习基础团队陆续发布了小型语言模型(SLM)Phi系列。
其中,第一个模型为13亿参数规模的Phi-1,官方博客称,Phi-1在SLM中的Python编码方面表现最好,在HumanEval和MBPP基准测试上尤甚。第二个模型为13亿参数规模的Phi-1.5,这个模型的重点为常识推理和语言理解能力。
现在微软发布的Phi-2能为研究人员探索机器可解释性、安全性改进或对各种任务的微调实验上提供帮助,目前,Phi-2已经从Azure AI Studio模型目录中开放给研究人员。
一、96块A100 GPU训练14天,参数规模仅27亿
一些大模型的参数规模达到数千亿的量级,使得其涌现出众多新兴能力,那么,是否可以通过改变训练策略等方式让更小的参数实现这些能力?微软的小型语言模型(SLM)系列或许是这一问题的答案。
Phi-2是一个基于Transformer架构的模型,具有下一个单词预测目标,在用于NLP和编码的合成数据集和Web数据集的混合上多次传递的1.4T tokens上进行训练。
Phi-2在96个A100 GPU上训练了14天,作为一个基础模型,其没有通过人类反馈强化学习(RLHF)进行对齐,也没有进行指令微调。
尽管如此,与经过调整的现有开源模型Llama 2-7B相比,研究人员观察到在避免生成有攻击性、有害和内容有偏差方面Phi-2的表现也不差。
研究人员根据ToxiGen的13个人口统计数据计算的安全评分,他们选择6541个句子的子集,并根据困惑度和句子“毒性”进行0到1之间的评分。分数高就说明,模型产生有攻击性、有害句子的可能性较小。
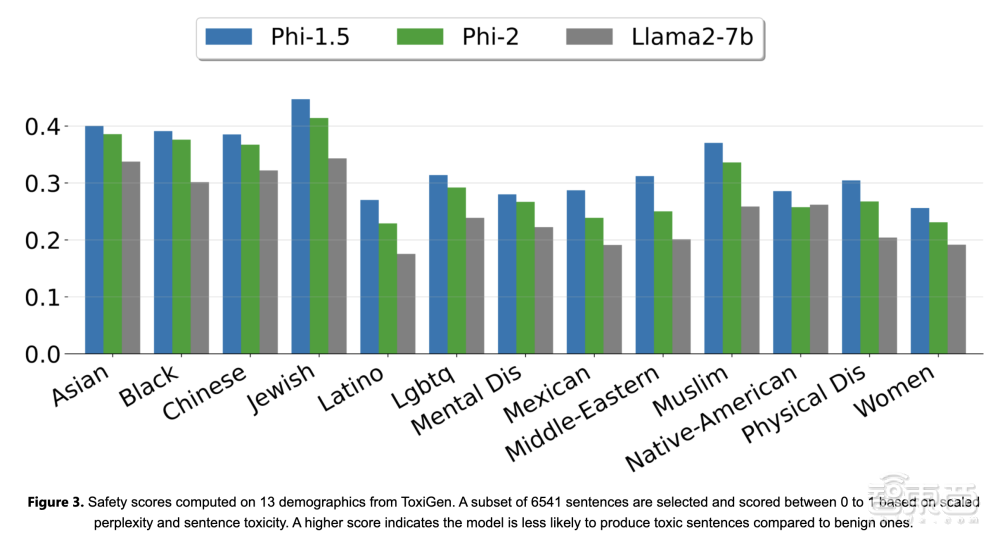
▲Llama 2与Phi-2在生成有攻击性、有害和内容有偏差方面性能比较(图源:微软官方博客)
微软使用Phi-2打破了传统语言模型缩放定律,其中有两个关键环节:
第一是训练数据的质量对模型的性能至关重要。微软的模型训练数据包含专门创建的合成数据集,用于教授模型常识推理,还包括科学、心理等领域的常识。
研究人员还挑选了一些网络数据进一步扩充训练语料库,并基于内容的价值和质量进行了数据过滤。
此外,从13亿参数规模的Phi-1.5开始,微软的研究人员实现了规模化的知识转移,将Phi-1.5的知识嵌入到27亿参数的Phi-2中。这种方法不仅加速了训练收敛,而且提高了Phi-2的基准分数。
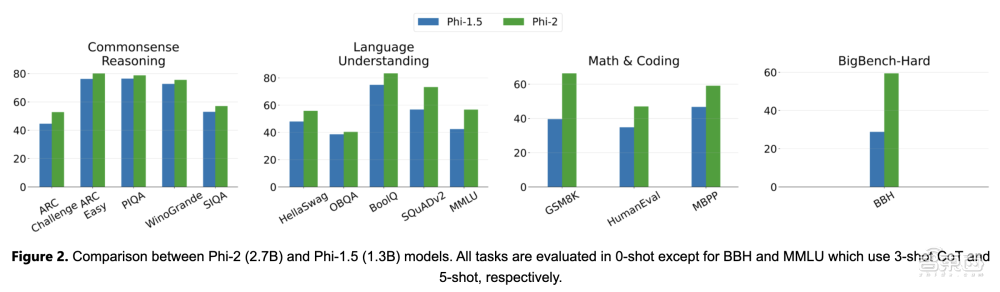
▲Phi-2和Phi-1.5比较(图源:微软官方博客)
二、基准测试击败Llama 2、Mistral、Gemini Nano 2
微软总结了Phi-2在学术基准上与主流语言模型的性能表现对比。
其基准测试涵盖Big Bench Hard(BBH数据集)以及PIQA、WinoGrande、ARC easy、Challenge、SIQA的常识推理、HellaSwag、OpenBookQA、MMLU、SQuADv2的语言理解数据集,GSM8k数学数据集和HumanEval、MBPP的编码数据集等。
27亿参数规模的Phi-2,在BBH、常识推理、语言理解、数学、编码各项基准测评上都超过了70亿、130亿参数规模的Mistral和Llama 2。
相比于参数规模差距在25倍的700亿参数Llama 2,Phi-2在编码、数学等多步推理任务上表现更好。

▲Llama 2、Mistral、Phi-2性能比较(图源:微软官方博客)
此外,微软还比较了Phi-2与谷歌最近发布的Gemini Nano 2,谷歌发布的模型参数规模为32.5亿,Phi-2的性能表现部分优于Gemini Nano 2。

▲Phi-2、Gemini Nano 2性能比较(图源:微软官方博客)
考虑到一些公共基准测试的数据可能会泄漏到训练数据中,微软对第一个模型Phi-1进行了广泛的净化研究以排除这种可能性。
基于判断语言模型的最佳方法是在具体用例上对其进行测试的考量,研究人员使用了多个微软内部专有数据集和任务评估了Phi-2,并再次将其与Mistral和Llama 2进行比较,其结果为,平均而言Phi 2优于Mistral-7B,后者优于70亿、130亿、730亿参数规模的Llama-2模型。
除了基准测试外,研究人员还测试了社区内的一些常用提示,他们观察到的表现也与基准测试的结果预期一致。
其中,研究人员测试了用于评估谷歌Gemini Ultra模型在解决物理问题方面能力的问题。

与Gemini的测试类似,研究人员进一步向Phi-2询问学生的错误答案,来确认它是否能识别出错误所在。
不过,从输出结果来看,这并不完全是与Gemini报告中描述的Gemini Ultra输出的同类比较,Gemini测评中学生的答案上传了手写文本的图像,Phi-2的测试采用的是原始文本。

结语:大模型时代,小模型仍在崛起
Phi-2的参数规模仅有27亿,但相比于参数规模更大的70亿、130亿模型,其性能表现仍不逊色。微软专注于小模型市场的布局,也印证了大模型时代小模型的价值。
微软与OpenAI的紧密合作,使得GPT模型的表现在大模型市场一骑绝尘,再加上微软参数规模更小的Phi系列,能进一步抢占开源模型长尾市场。不过从目前来看,Phi系列仅被允许用于研究目的。
从市场来看,越来越多的玩家开始探索在手机等移动设备上部署大模型,微软此举或许也会加速模型能力在端侧的应用。
https://zhidx.com/p/407141.html
More articles on Future Tech
Launch costs hit Sonova's profit, as it bets on new product with AI tech
Created by Tan KW | Nov 19, 2024
Windows 95 setup was three programs in a trench coat, Microsoft vet reveals
Created by Tan KW | Nov 19, 2024
Has Apple's latest update solved the final problem of lost luggage?
Created by Tan KW | Nov 19, 2024
Meta to appeal Indian order that curbs data-sharing between WhatsApp, other apps
Created by Tan KW | Nov 19, 2024
Indian news agency ANI sues OpenAI for unsanctioned content use in AI training
Created by Tan KW | Nov 19, 2024
iOS 18 added secret and smart security feature that reboots iThings after three days
Created by Tan KW | Nov 19, 2024
Thai fimin says phase two of digital wallet will cover 4 million people
Created by Tan KW | Nov 19, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts
Introducing MY's First IPO Fund for Sophisticated Investors!
New Update. Discover investment communities that resonate with your ideas
M & A Value Partners IPO Equity Fund has been launched - Targeted 13% Return p.a
Latest Videos





Apps


Top Articles
1
2
BFM Podcast
4
BFM Podcast
6
BFM Podcast
7
BFM Podcast
8
BFM Podcast
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....