





Future Tech
[转贴] AIGC工作站要把好三道关,宁畅为AI时代终端算力打了个样


智东西(公众号:zhidxcom)
作者 | 香草
编辑 | 漠影
在5G、边缘计算等技术的推动下,算力逐渐从数据中心向终端扩展。AI时代的终端算力,应该是什么样子?
智东西6月27日报道,昨日,宁畅在第五届中国智算中心全栈技术大会上发布了自驱式相变液冷AI工作站,将液冷技术从智算中心拓展至桌面端,为终端算力注入新的活力。

▲宁畅自驱式相变液冷AI工作站(图源:宁畅)
如果说自驱式相变液冷AI工作站,是宁畅在“全液冷”产品上的重要实践,那么其月初推出的首款专业级桌面工作站/塔式服务器W350 G50,则是宁畅在“全体系”终端产品形态上迈出的第一步。

▲宁畅W350 G50工作站(图源:宁畅)
这两款AI工作站,均是宁畅“全局智算”战略版图的最新实践。今年3月,宁畅正式发布“全局智算”战略,率先开启大模型时代智能算力系统变革的冲锋,为行业提供全栈智能计算能力,以及涵盖硬件、软件、算法、液冷和服务质量等多个维度的系统性AI计算方案。
其中,W350 G50是宁畅首款专业级桌面工作站/塔式服务器,搭载NVIDIA RTX™ 4000 Ada & RTX™ 5000 Ada GPU,为高端图形处理场景提供强大又灵活的算力支撑,具备强劲性能、丰富拓展、灵活管理三大优势。
作为多年专注于服务器的厂商,宁畅为什么要做桌面级工作站产品?其能解决哪些行业痛点,带来什么样的新质生产力?在宁畅“全局智算”战略中,W350 G50扮演什么角色?本文对此进行了深入探讨。
一、AIGC驱动生产力工具变革,“桌面级智算中心”交卷
AIGC正在各行各业蓬勃发展,从内容创作、智能客服,到医疗诊断、金融预测等行业场景,都有着AIGC应用的身影。
然而对于中小企业和开发者而言,高昂的算力成本成为制约其开发和落地应用的关键因素。大模型的训练和推理需要大量计算资源,无论是购置和维护算力设备,还是租用云服务厂商的高端算力,都带来极高的财务压力。
如何压缩算力成本,将先进的AIGC技术与实际业务场景相结合,创造有效的应用价值?这是众多企业和开发者亟待解决的难题。高效、低成本且易于落地应用的算力解决方案成为了市场的迫切期待。
在这样的背景下,宁畅以桌面级AI工作站W350 G50交卷,通过对硬件的优化和对扩展能力的提升,将服务器或数据中心级别的算力带到桌面上。

▲宁畅W350 G50工作站(图源:宁畅)
宁畅W350 G50搭载NVIDIA RTX™ Ada架构,是一款基于英特尔至强W790芯片的4U机塔互换工作站,最大支持56核112线程、112条PCle 5.0,可支持3块双宽GPU卡。
面向科研、制造、电影、设计、动画、建筑、机械等高端图形处理用户,宁畅W350 G50兼容主流的图形设计软件,并专门针对CAD、仿真模拟、动画制作、CG渲染、图形计算等应用进行了优化。
例如在科研领域,前沿的模型训练对算力要求极高,宁畅W350 G50强大的算力能够大幅缩短数据处理时间,加快科研成果的产出。
在制造业领域,宁畅W350 G50可以加速产品的模拟分析,提高设计效率,快速响应市场需求。
在影视行业,特效制作往往需要大量的计算资源和时间,宁畅W350 G50的图形处理能力可以加快渲染速度,显著缩短特效制作周期,提高影视制作整体效率。
总的来看,宁畅的桌面级AI工作站提供了一种创新的解决方案,通过硬件优化和扩展能力的提升,将原本属于服务器或数据中心的高性能算力,以更加经济的方式带给了中小企业,不仅响应了市场对于高效、低成本算力解决方案的需求,也为中小企业和开发者在AIGC领域的应用和发展提供了强有力的支持。
二、宁畅AIGC工作站把好三道关:性能、扩展和管理
作为一款全能AIGC工作站,宁畅W350 G50具备三大亮点:强劲性能、丰富拓展、灵活管理。
在性能方面,其基于NVIDIA RTX™ Ada 架构,单CPU最高56核心112线程,能够轻松应对复杂的计算任务,无论是大规模的数据处理、深度学习模型的训练,还是高要求的图形渲染,都能迅速而高效地完成。
在拓展能力方面,宁畅W350 G50支持全系列专业显卡,包括RTX 5880 Ada、RTX A5000等,具备广泛的适用性和升级潜力;最大支持3块全高、全长、双宽的专业图形卡或GPU卡,可用于复杂的图形处理和计算加速;多种形态的I/O接口方便用户连接各类外部设备,满足不同工作场景的特殊需求。

▲宁畅W350 G50的I/O接口(图源:宁畅)
在管理方面,宁畅W350 G50支持塔式和机架式灵活切换,既能够作为高端桌面工作站,也可作为微型服务器转换为数据中心模式;同时支持IPMI远程管理,管理员可以在异地对工作站的运行状态进行实时监测和控制,及时处理可能出现的问题,减少维护成本和停机时间;支持冗余电源、企业级部件等,能带来服务器级别的专业体验。
结合NVIDIA Ominiverse平台,宁畅W350 G50可聚焦AIGC、数字孪生等场景,对复杂的工业系统、城市基础设施甚至整个生态系统进行高精度的模拟和仿真,为内容创作者提供更加高效的创作环境。
从市场需求来看,宁畅W350 G50满足了市场对于高性能AI终端解决方案的迫切需求,尤其是在云端算力成本高昂和部署复杂性成为制约因素的背景下。
具体到不同的应用场景中,宁畅W350 G50表现如何?
近日,专注企业设备开箱的科技UP主“无情开评”对W350 G50在文生图、AI对话、图生视频、3D渲染等工作任务上的表现进行了测试。
配备一块RTX™️ 4000 Ada后,UP主测试了英伟达聊天机器人ChatRTX在W350 G50上的运行情况。基于默认的Mistral模型,其迅速生成了一个配置交换机的Python程序,几乎是秒级生成,同时GPU占用仅有6.8G。
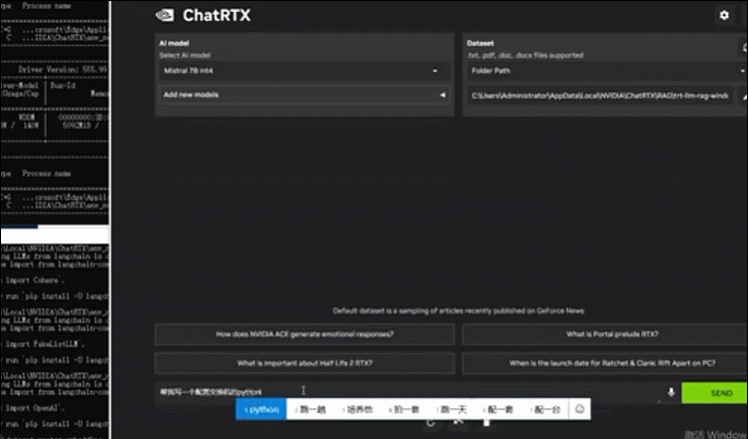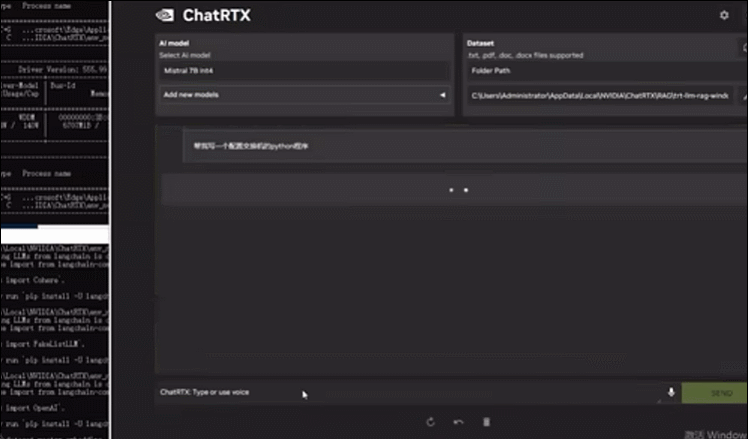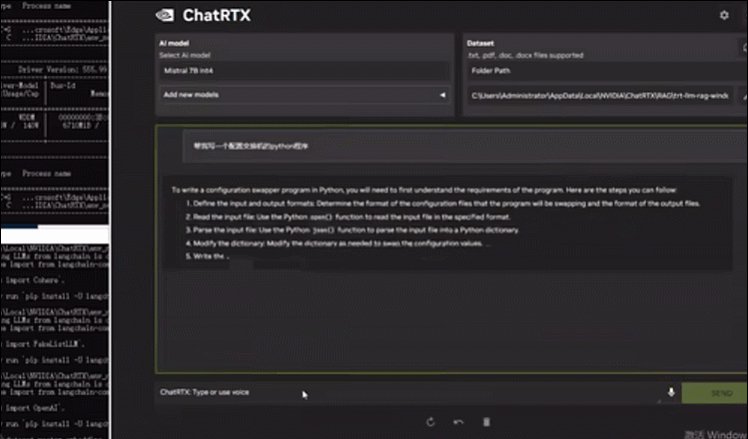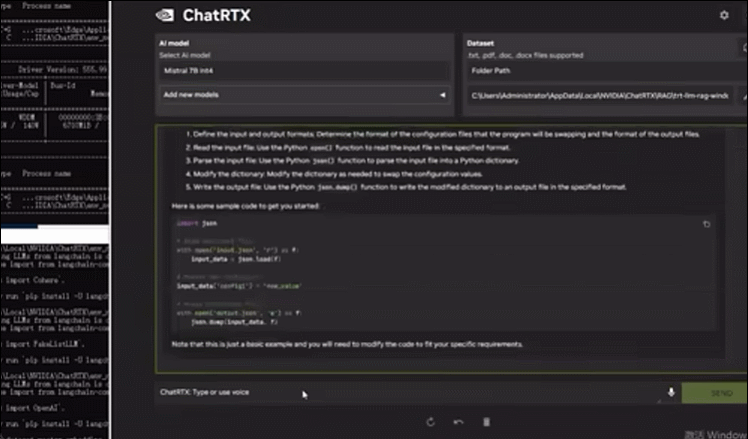
▲宁畅W350 G50运行Mistral模型
此外在GPU加持下,UP主再次以相同的要求测试了文生图的速度,结果显示生成同样的20组图像仅耗时3分50秒。
在后期制作方面,UP主将W350 G50与市面上其他普通工作站进行对比,在相同的渲染任务下,普通工作站用时7分钟,W350 G50仅用时3分钟,节省了一半以上的时间。
在C4D渲染任务上,UP主进行了单卡和双卡对比测试,结果显示两次渲染GPU占用率都达到100%,在时间上单卡渲染用时1分19秒,双卡只需要40秒,再次证明了W350 G50的并行处理能力。
从整体测试结果看来,宁畅W350 G50在多种生成式AI和传统图形处理任务上都表现出色,资源利用率高、多任务并行处理能力强,能够为图形、AI密集型任务提供显著的生产效率提升。这些特性不仅满足了当前企业对于高性能计算的需求,更预示了未来工作站发展的趋势。
三、打造AI时代“全局智算”,开创终端产品形态先驱
今年3月,宁畅正式发布“全局智算”战略,率先开启大模型时代智能算力系统变革的冲锋,希望通过全栈智能计算能力,以及涵盖硬件、软件、算法、液冷和服务质量等多个维度的系统性AI计算方案,为更多行业发展带来支持和动力。

▲宁畅全局智算发布会(图源:宁畅)
据宁畅总裁秦晓宁解读,“全局智算”具备六大“全”特性——全体系、全液冷、全服务、全场景、全行业、全阶段,按用户发展阶段,定制专业且性价比高的AI计算方案。
在“全体系”“全液冷”的指引下,宁畅于5月30日发正式发布“全栈全液”AI基础设施方案,在业内首先实现了软硬兼备、全栈全液的智算中心建设能力,推动智算中心发展迈入新阶段。

▲宁畅“全栈全液”AI基础设施方案(图源:宁畅)
针对科研计算、仿真模拟、影视渲染等高功耗计算场景,宁畅将原本用于智算中心的液冷技术,创新性地融入到AI工作站设计中,在有限空间实现高效散热,确保算力的持续高效地输出。
同时,宁畅于战略发布时同步推出的“AI算力栈”也开放免费试用,其是一个包括128台GPU服务器的千卡级别算力集群,囊括羽量级128、轻量级256、中量级512、重量级1024四个等级,截至5月底已有50+用户预约试用。
大模型时代,智算中心需要具备“AI全能力”,这意味着其不仅要有强大的硬件设施来支持海量数据的处理和复杂模型的训练,还要拥有先进的软件系统来实现高效的资源管理和调度。
推出首款桌面级终端产品,是宁畅践行全局智算战略的重要动作和先锋实践,实现了从数据中心到桌面的全场景覆盖。
基于多年服务器研发、生产经验,宁畅W350 G50成为一款集大成的终端产品,从性能、功能、智能三维度带来“AI工作站标杆之作”。
“全局智算”战略以及“全栈全液”AI基础设施方案,体现了宁畅对当前AI大模型时代需求的深刻理解,也展现了其在推动行业发展和技术创新方面的领导力。随着这些方案的深入实施和不断完善,宁畅为智能算力领域带来了新的发展机遇,也为各行业的数字化转型提供了有力的支持。
结语:大模型加速落地,AI算力桌面时代来临
随着大模型的不断发展和应用,AI算力的需求也在迅速增长。智算中心是AI时代的“水电站”,在推动行业数字化转型、促进AI产业化落地的重要性不言而喻。
而随着大模型计算不断向边缘侧扩展,传统的集中式计算模式已经无法满足日益增长的算力需求,桌面级算力应运而生。将算力扩展到桌面,不仅可以提高计算效率,降低计算成本,还可以更好地保护用户的数据隐私。
在“全局智算”战略的指引下,宁畅正在交出自己的算力解决方案答卷,为各行业的数字化转型和智能化升级保驾护航。
https://zhidx.com/p/431095.html
More articles on Future Tech
Musk also wants to fight Microsoft in legal grudge match with OpenAI
Created by Tan KW | Nov 16, 2024
Photoshop FOSS alternative GNU Image Manipulation Program 3.0 nearly here
Created by Tan KW | Nov 16, 2024
Google Gemini tells grad student to 'please die' while helping with his homework
Created by Tan KW | Nov 16, 2024
Keyboard robbers steal 171K customers' data from AnnieMac mortgage house
Created by Tan KW | Nov 16, 2024
Musk expands lawsuit against OpenAI, adding Microsoft and antitrust claims
Created by Tan KW | Nov 16, 2024
Apple deletes US-funded RFE/RL news app from Russian App Store, news outlet says
Created by Tan KW | Nov 16, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts
Introducing MY's First IPO Fund for Sophisticated Investors!
New Update. Discover investment communities that resonate with your ideas
M & A Value Partners IPO Equity Fund has been launched - Targeted 13% Return p.a
Latest Videos





Apps


Top Articles
1
BFM Podcast
2
BFM Podcast
4
5
6
7
BFM Podcast
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....