





Future Tech
[转贴] 最强开源大模型一夜封神!Llama 3.1震撼发布,真正的全民GPT-4时代来了


智东西(公众号:zhidxcom)
作者 | 智东西编辑部
智东西7月24日报道,昨夜,Meta宣布推出迄今为止最强大的开源模型——Llama 3.1 405B,同时发布了全新升级的Llama 3.1 70B和8B模型。
Llama 3.1 405B支持上下文长度为128K Tokens,在基于15万亿个Tokens、超1.6万个H100 GPU上进行训练,这也是Meta有史以来第一个以这种规模进行训练的Llama模型。
研究人员基于超150个基准测试集的评测结果显示,Llama 3.1 405B可与GPT-4o、Claude 3.5 Sonnet和Gemini Ultra等业界头部模型媲美。

除了性能强劲外,Meta创始人兼CEO马克·扎克伯格还亲自发文助阵,他称,除了比闭源模型成本和性能更优,405B开源模型将成为企业微调和训练较小模型的最佳选择。
Meta AI宣布接入Llama 3.1 405B,并推出AI图片编辑、AI编程、VR/AR设备智能助手等新功能。扎克伯格预测, Meta AI助手使用率几个月后将超越ChatGPT。

▲Meta AI支持Quest头显与用户实时音视频交互
Meta的开源生态圈也已准备就绪。Meta与超过25个合作伙伴将提供Llama 3.1模型,包括亚马逊AWS、NVIDIA、Databricks、Groq、戴尔、微软Azure和谷歌云等。
迄今为止,所有Llama模型版本的总下载量已经超过3亿次,与主流闭源模型能力相当的Llama 3.1模型发布或许意味着,Meta要讲的开源模型故事刚刚开始……

模型下载链接:
https://huggingface.co/meta-llama
论文链接:
https://t.co/IZqC6DJkaq

▲Meta Llama 3.1模型论文解读摘要
一、405B开源模型对标GPT-4o,25家合作伙伴已就绪
Meta评估了超150个基准数据集的性能,Llama 3.1 405B在常识、可操作性、数学、工具使用和多语言翻译等一系列任务中,可与GPT-4o、Claude 3.5 Sonnet和Gemini Ultra相媲美。
在现实场景中,Llama 3.1 405B进行了与人工评估的比较,其总体表现优于GPT-4o和Claude 3.5 Sonnet。

升级后的Llama 3.1 8B和70B模型,相比于同样参数大小的模型性能表现也更好,这些较小参数的模型支持相同的128K Tokens上下文窗口、多语言、改进的推理和最先进的工具使用,以支持实现更高级应用。

Meta更新了许可证,允许开发人员首次使用包括405B参数规模的Llama模型的输出来改进其他模型。
同时,Meta的开源生态进一步扩张,已经有超过25个企业推出了Llama 3.1新模型。
其中,亚马逊云科技、Databricks和英伟达正在推出全套服务,以支持开发人员微调和训练自己的模型。AI芯片创企Groq等为Meta此次发布的所有新模型构建了低延迟、低成本的推理服务。
同时这些模型将在亚马逊云科技、微软Azure、谷歌云、Oracle等主要云平台上提供服务。
Scale AI、戴尔、德勤等公司已准备好帮助企业采用Llama模型并使用自己的数据训练定制模型。
Llama 3.1 405B不仅是最强开源模型,还有望成为最强模型,开源和闭源的距离再次大大缩短。
二、完整优化训练堆栈,专注于让模型可扩展
为了能基于15万亿个Tokens进行模型训练,同时在合理时间内实现研究人员想要的效果,Meta对训练堆栈进行了完整优化。

在解决上述难题方面,Meta选择专注于保持模型开发过程可扩展并更直接的策略:
1、研究人员选择了标准仅解码器的Transformer模型架构进行小幅调整,而不是采用MoE混合专家模型,可以最大限度提高训练稳定性。
2、研究人员采用了迭代的后训练程序,每轮都使用监督微调和直接偏好优化。这使模型能够为每一轮创建最高质量的合成数据,并提高每项能力的性能。
与此前Llama系列模型相比,Meta改进了用于训练前和训练后的数据的数量和质量。这些改进包括为训练前数据开发更仔细的预处理和管理pipelines、开发更严格的质量保证,以及训练后数据的过滤方法。
正如大语言模型的Scaling Laws(规模定律)所预期的那样,Meta新旗舰模型优于使用相同策略训练的较小模型。Meta还使用405B参数的模型提高了其较小模型的训练质量。
同时,为了支持405B参数模型的大规模推理,研究人员将模型从BF16到FP8进行了量化,有效降低了所需的计算要求,并允许模型在单个服务器节点内运行。
在指令和聊天微调方面,研究人员通过在预训练模型之上进行几轮对齐以生成最终模型,每一轮都涉及监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO),其使用合成数据生成来生成绝大多数SFT示例以生成所有功能中更高质量的合成数据。
此外,Meta采取了多种数据处理技术以将这些合成数据过滤到最高质量,这使新模型能够跨功能扩展微调数据量。
在数据方面,研究人员还对数据进行了仔细平衡以生成具有所有功能的高质量模型。例如,在短上下文基准上保证模型质量,使其能扩展到128K上下文长度。
此外,Meta还宣布推出一个整体的Llama系统。该系统除了涵盖Llama模型,还涉及多个组件协调及外部工具调用,以此助开发者开发比基础模型更强的定制产品。
Llama系统将涵盖一系列新组件,包括开源新的安全工具如Llama Guard 3(多语言安全模型)和Prompt Guard(即时注入过滤器)。为了让分散的组件联接起来,Meta还发布了对Llama Stack API的评论请求,这是一个标准接口,以此第三方项目更轻松地利用Llama模型。
对于普通开发者来说,使用405B规模的模型仍是一项挑战,这需要大量的计算资源和专业知识。
基于Llama系统,生成式AI开发不仅仅是提示模型,每个人都应该可以利用405B模型完成更多的任务,包括实时和批量推理、监督微调、针对特定应用评估模型、持续预训练、检索增强生成(RAG)、函数调用、合成数据生成等。
这是Meta迄今为止推出的最大模型,未来将推出更多设备友好的尺寸、更多模式以及在Agent层面的更新。
三、405B大模型爆改Meta AI,Quest智能语音助手升级
现在,Meta旗下的多个终端,比如WhatsApp和Meta AI聊天机器人中都开始使用Llama 3.1 405B。
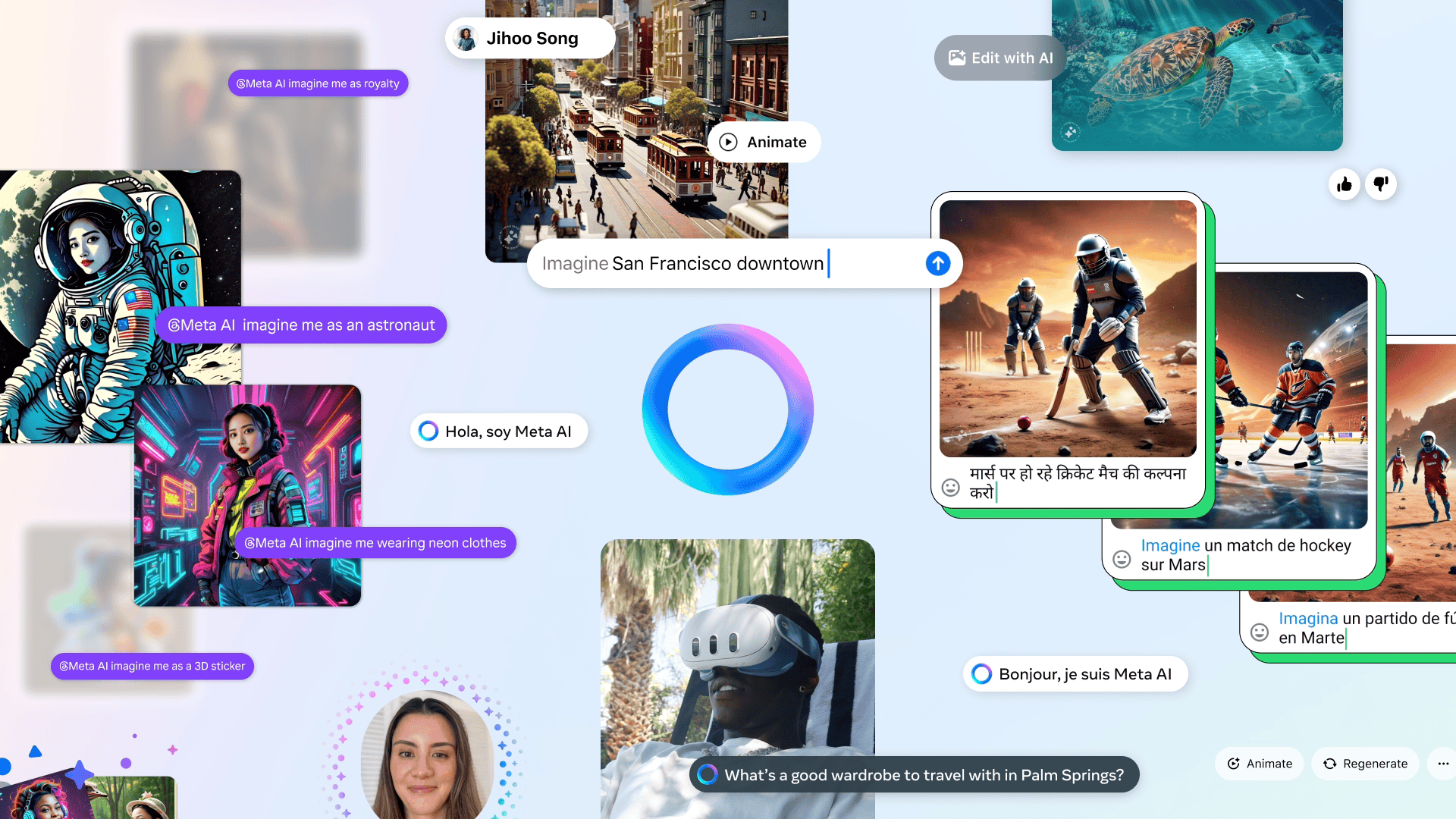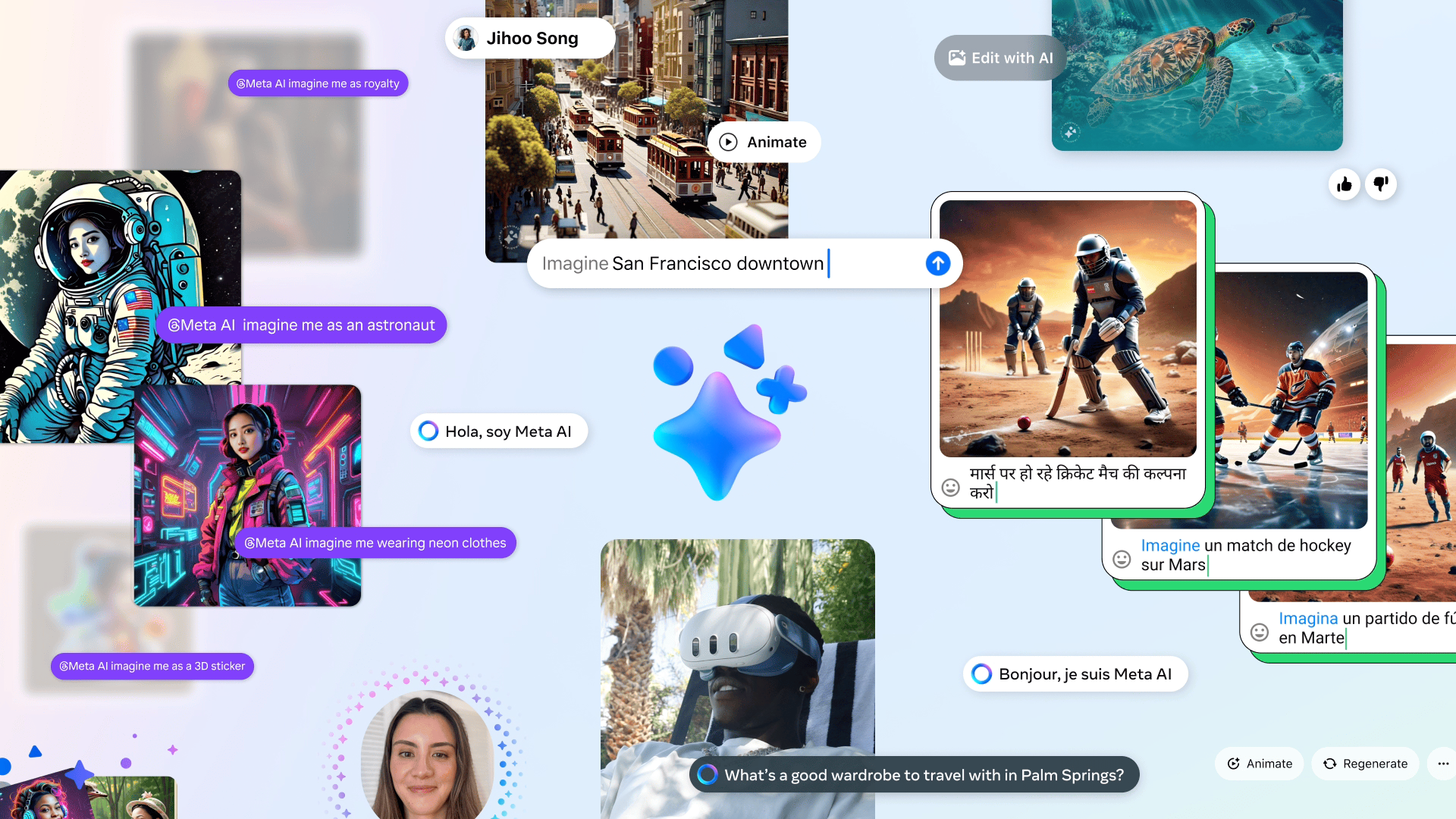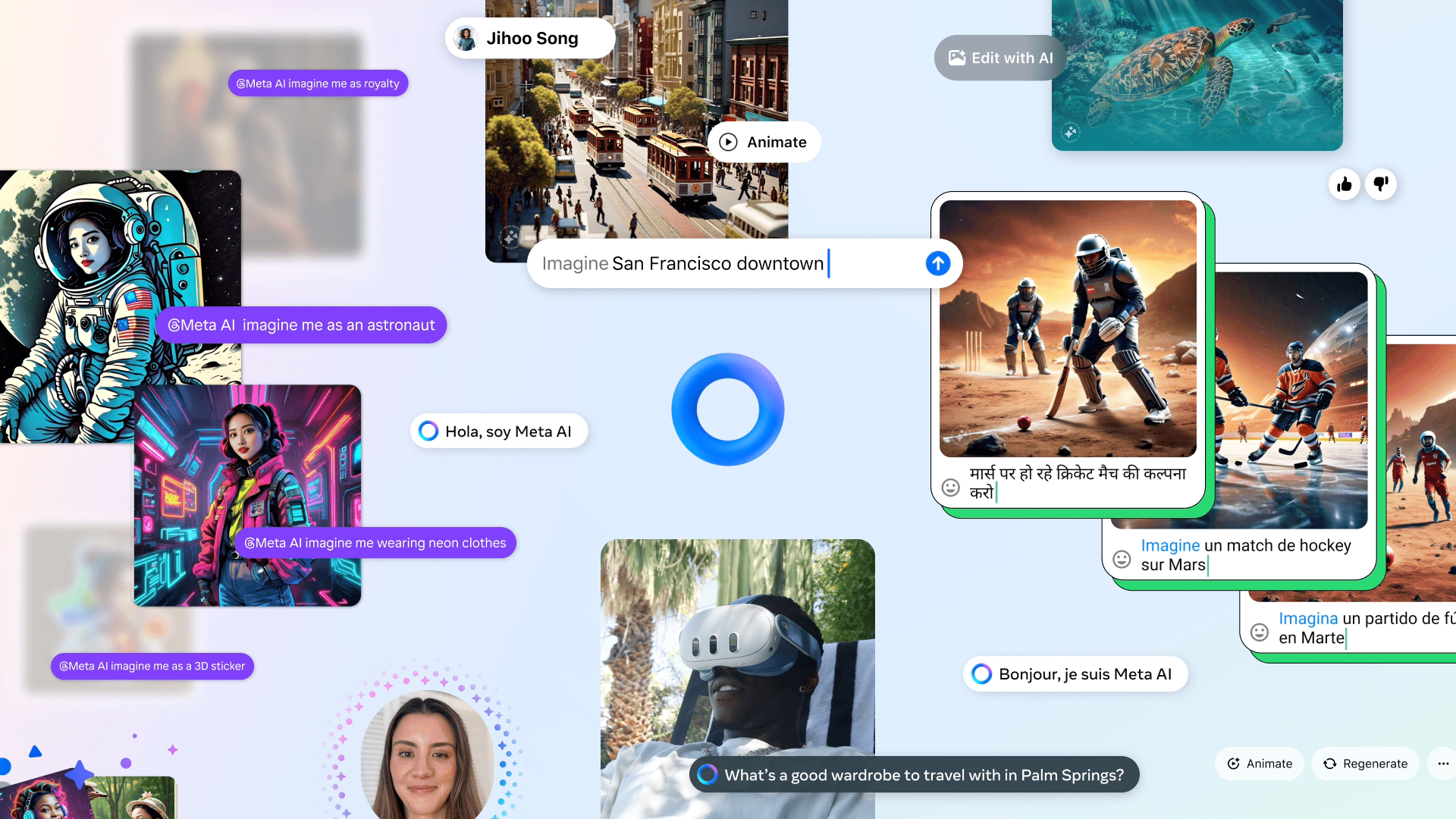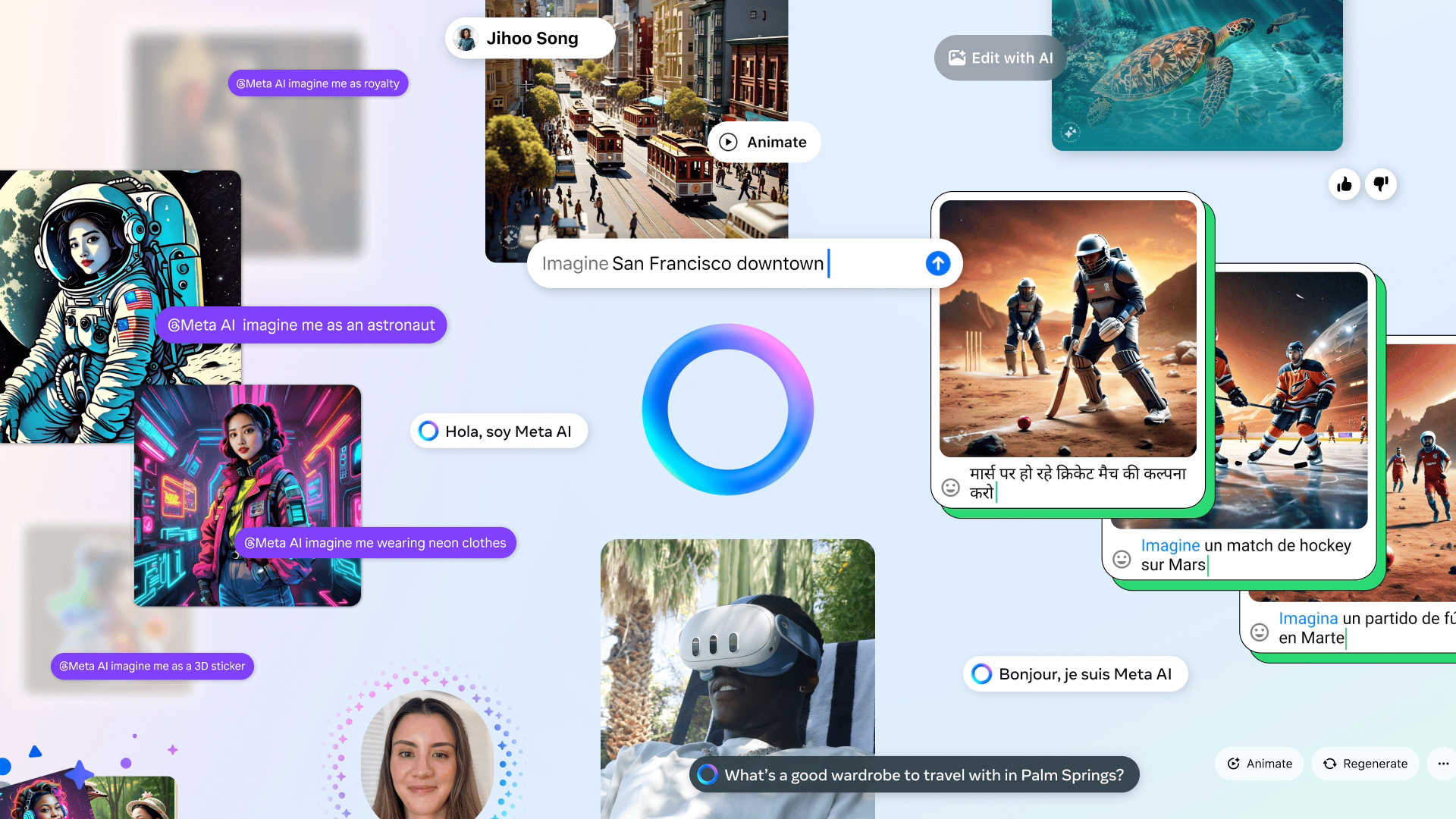
Meta AI目前已支持七种新语言,本次Meta推出一批新的Meta AI创意工具,主要聚焦视觉生成、数学和编码等领域。
首先看看视觉生成,Meta AI推出“想象我(Imagine Me)”图像生成提示功能,支持用户在Meta AI聊天中输入“想象我”并添加提示,例如“想象我是皇室成员”或“想象我在一幅超现实主义绘画中”,就可以生成图像并与朋友和家人分享。

Meta AI将上线“使用AI编辑(Edit With AI)”功能,用户可以通过点击鼠标轻松添加或删除对象,或更改和编辑它们 ,并保持图像的其余部分不变,比如将“将猫改为柯基犬”。Meta AI还将支持将新制作的图片添加到Facebook帖子中,以及Instagram、Messenger和WhatsApp等社交平台上。

在数学和编程方面,用户可以通过分步解释和反馈获得数学作业方面的帮助,通过调试支持和优化建议更快地编写代码,并通过专家指导掌握复杂的技术和科学概念。
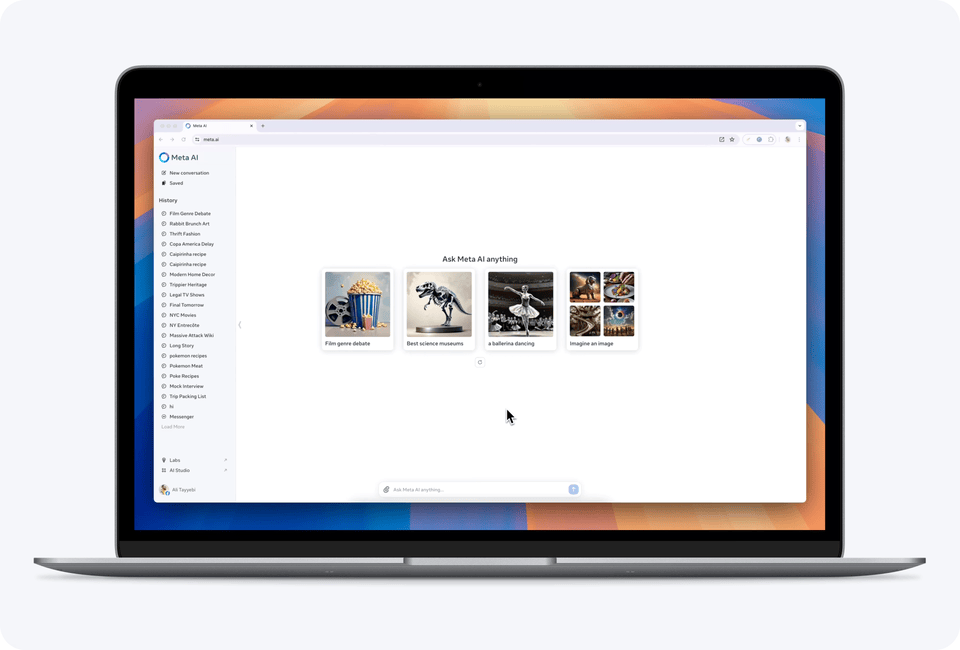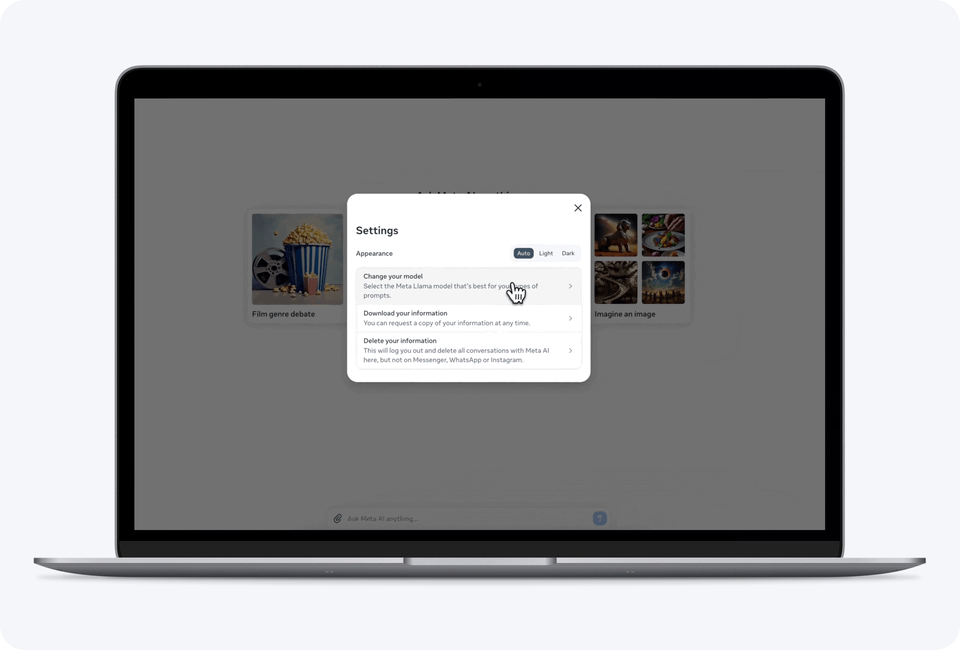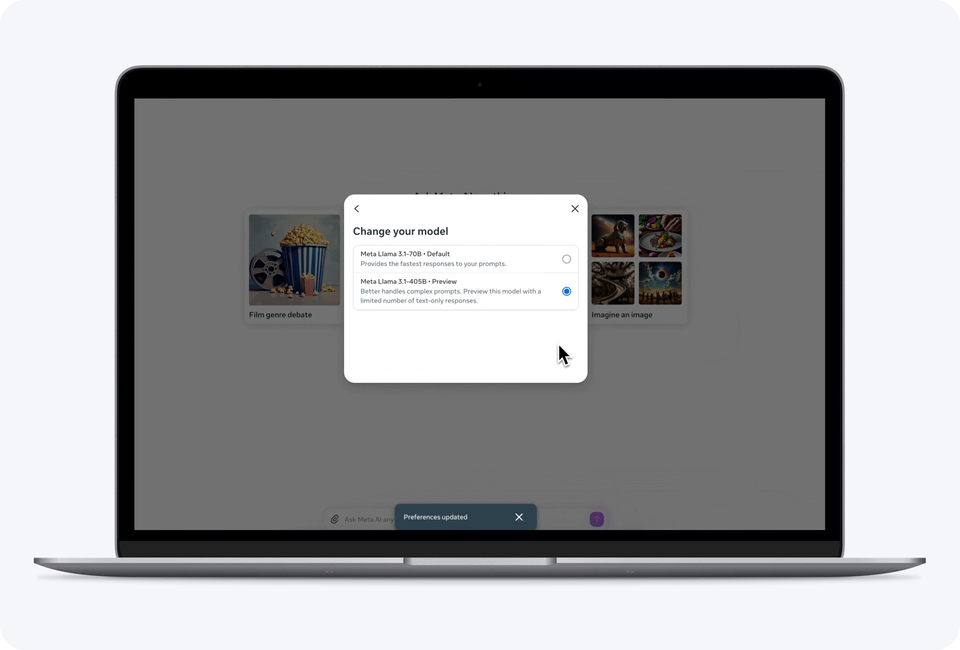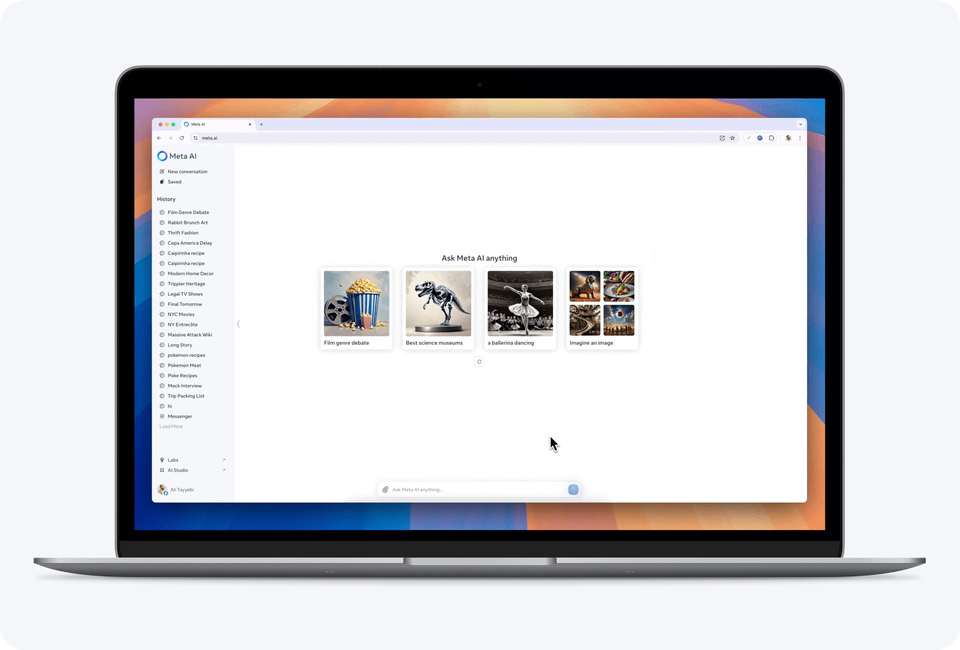
用户可以结合Meta AI的编码专业知识和图像生成功能,从头开始构建新游戏或对经典游戏进行全新演绎。只需几分钟即可将奇思妙想变成现实,甚至让用户直接预览游戏。
值得一提的是,Meta AI也适用于雷朋Meta智能眼镜,并将于下个月在美国和加拿大的Meta Quest上以实验模式推出。Meta AI将取代Quest上当前的语音命令,让用户可以免提控制耳机、获取问题的答案、随时了解实时信息、查看天气等。
用户还可以将Meta AI与在头显中看到的视图结合使用,比如询问其在物理环境中看到的事物相关情况。
四、扎克伯格公开信:开源对开发者、Meta、世界都更有利
Llama 3.1系列刚发布,扎克伯格的长篇博客同时上线官网,使得开闭源模型之间的火药味更浓了。

▲扎克伯格公开信部分截图
一开始,扎克伯格就提到开源模型与闭源模型之间的差距正在逐渐缩小。去年,Llama 2仅与上一代最先进的闭源模型相当。今年,Llama 3可与最先进的模型媲美,并在某些领域处于领先地位。
从明年开始,他预计Llama模型将成为业内最先进的模型。并且当下Llama系列模型已经在开放性、可修改性和成本效益方面处于领先地位。
在博客中,他直指闭源模型,回答了为什么开源AI对开发者有利、为什么开源AI对Meta有利、为什么开源AI对世界有利这三大问题。
首先,为什么开源AI对开发者有利?
他认为开发者需要训练、微调自己的模型,以满足各自的特定需求;开发者需要掌控自己的命运,而不是被一家封闭的供应商所束缚;开发者需要保护自己的数据;开发者需要高效且运行成本低廉的模型;开发者希望投资于将成为长期标准的生态系统。
开源AI对Meta的好处在于,Meta的商业模式是为人们打造最佳体验和服务,要做到这一点,他认为必须确保其始终能够使用最佳技术,并且不会陷入竞争对手的封闭生态系统。
同时,开源AI会促使Meta将Llama发展为一个完整的生态系统,并有成为行业标准的潜力。
他还提到,Meta与闭源模型玩家之间的关键区别之一是,出售AI模型访问权限不是Meta的商业模式,这意味着开源不会削减其收入、可持续性发展或继续投资研究的能力。
最后就是Meta拥有悠久的开源项目和成功历史。
关于开源AI模型安全性的争论,扎克伯格的观点是开源AI将比其他选择更安全。他认为开源将确保全世界更多的人能够享受AI带来的好处和机会,权力不会集中在少数公司手中,并且该技术可以更均匀、更安全地应用于整个社会。
结语:Meta再度落子,大模型开闭源之争生变
开闭源大模型之争仍在继续……
从Meta Llama 3.1系列模型的发布,可以看出开闭源大模型之间的差距正在缩小,且大有齐头并进、互相赶超之势。作为开源大模型阵营的忠实拥趸者,同时也是技术创新的先锋,Meta从Llama系列模型发布之初,就坚定要打造自己的开源生态圈。同时,相比于此前的Llama模型,此次新模型发布Meta还将在内部组建团队,让尽可能多的开发人员和合作伙伴使用Llama系列。
Meta再度落子,使得开闭源模型之争的定论更加扑朔迷离。但归根结底,在实际应用中,很多企业和开发者会根据具体需求和情况选择使用开源或闭源模型,因此模型的具体能力、适用的真实场景等,还需要时间来证明。
https://zhidx.com/p/435046.html
More articles on Future Tech
Disney nears tipping point as streaming profits start to offset cable decline
Created by Tan KW | Nov 15, 2024
Kremlin says Putin is looking into issue of slow YouTube speeds in Russia
Created by Tan KW | Nov 15, 2024
That hardware will be more reliable if you stop stabbing it all day
Created by Tan KW | Nov 15, 2024
Samsung Electronics plans $7.2 billion buyback to boost shareholder value
Created by Tan KW | Nov 15, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts



Latest Videos





Apps


Top Articles
1
3
BFM Podcast
5
BFM Podcast
6
BFM Podcast
7
BFM Podcast
8
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....