





Future Tech
[转贴] 多模态时代来了!AI虚拟数字人,掀起百亿数据服务新蓝海


智东西(公众号:zhidxcom)
作者 | 心缘
编辑 | 漠影
写在前面:元宇宙、虚拟数字人概念火爆的2021,高质量训练数据资源正成为雄心勃勃的AI企业们解锁更强智能的关键燃料,通过对话国内唯一A股上市数据服务商海天瑞声,我们试图探讨隐藏于这场新兴技术浪潮幕后的基石角色,如何运用技术解决智能化升级过程中的核心痛点。
2022年,再不关注虚拟数字人,你就落伍啦!
在刚刚过去的一年,AI虚拟主播、虚拟学生、虚拟员工轮番上岗,成为元宇宙与人工智能两大领域最热门的技术赛道之一。
 ▲万科首位数字化员工崔筱盼获得万科总部最佳新人奖
▲万科首位数字化员工崔筱盼获得万科总部最佳新人奖
有些虚拟数字人已经表现得灵性十足,不仅发音标准自然、身体动作流畅,就连眨眼频率、口型与声音的匹配等细节都惟妙惟肖。
这些火遍大江南北的特殊生命体,通过越来越多元的形象定制、舒适的交互体验,逐渐转变为拥有更接近真实人类智商和情感的新型社会角色。
而「多模态技术」,正是打破单一感官的藩篱,让AI虚拟形象越来越像人类的秘密武器。
一、破圈而来,“完美”虚拟人离不开的多模态
数据,是将真实世界与虚拟世界连接的桥梁。
在现实世界中,数据天然以「多模态」的形式存在,人类通过综合运用视觉、听觉、触觉、嗅觉等多种感官,来接触和理解大千世界。
为了探索实现通用人工智能(AGI)的路径,人工智能(AI)从单模态走向多模态已是大势所趋。
以前,Siri等语音助手只有声音没有脸,搜索只能依靠输入文字,机器看不懂照片的深层含义。
如今,借助多模态技术,AI实现了图像、视频、音频、语义文本等多维度资源的融合互补,不仅决策更加精准,还在行为和智商上更接近人类。
新冠疫情亦催化了多模态技术的落地进程。在隐私安全保护重视程度日益加强的趋势下,多模态生物识别凭借更高的准确率和安全性,正取代基于指纹、人脸等单一生物特征的身份识别方法。
而深藏多种黑科技的AI虚拟主播,亦是基于多模态技术的快速演进,成为感知智能迈向认知智能阶段的重要探索。
它们的精致面容、流畅表达、优美体态,离不开微表情追踪、语音识别、语音合成、自然语言理解、动作捕捉等丰富技术的支撑。
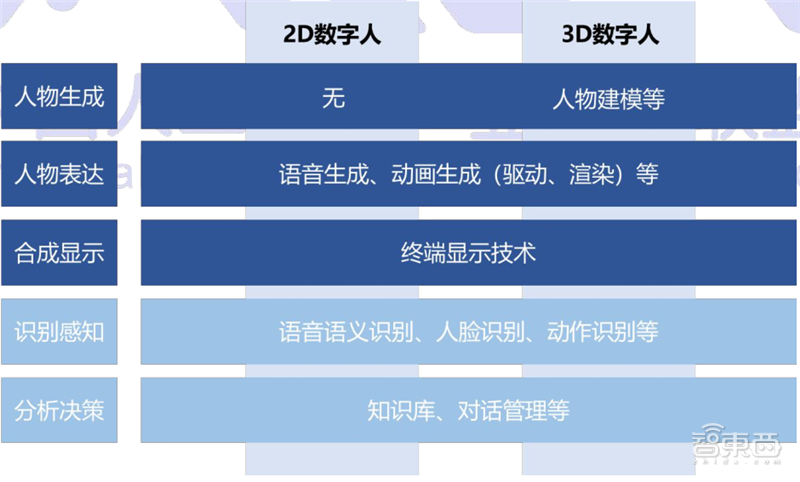 ▲虚拟数字人技术架构(来源:《2020年虚拟数字人发展白皮书》)
▲虚拟数字人技术架构(来源:《2020年虚拟数字人发展白皮书》)
其中,AI手语主播要解决的技术难点尤其复杂。为了照顾到听障人士的需求,它需要具备实时将中文、英文等语音“翻译”成连贯手语的能力。
但手语有一套独特的语法体系,如果来一段央视押韵狂魔朱广权的段子“冷空气非常强,但他强任他强,清风拂山岗,他横任他横,秋裤保健康”,那就极度考验AI手语主播的理解和翻译水准了。
要做到实时精确演示手语,AI主播需先将语音转化成文字,再将健听人士的文本语序转化成手语语序,最后基于手语数据集进行手语合成,将相同的信息以视觉的形式传递给听障人士。
在此过程中,获得符合需求的训练数据成为了最具挑战性的问题之一。
这是因为,作为一种视觉语言,手语语言远比语音语言模态复杂,既包含手型、手部位置等手控信息,又包含表情、口动、体态等非手控信息。
如果从2D视频来采集手语运动过程中的数据,则不可避免会遇到动作被遮挡、人脸五官各区域区分不明显、空间深度信息缺失等问题。
 ▲央视冬奥AI手语主播
▲央视冬奥AI手语主播
综合看来,通过专业设备采集的3D多模态数据,已经成为优化特定垂直场景AI虚拟数字人的智能化水平中,为数不多的解决方案之一。
怎样获得高品质的多模态训练数据库?AI基础数据服务商的商业价值开始日益凸显。
二、优质算法“杀手锏”:高质量数据背后的技术试炼
数据、算法、算力被并称为「AI三要素」,数据质量的高低,往往决定AI算法模型的性能上限。
随着AI应用逐渐普及,位于基础设施层的AI数据服务行业正发展地风生水起。根据知名市研机构IDC报告,到2025年,中国AI数据采标服务市场规模预计将增至123.4亿元。
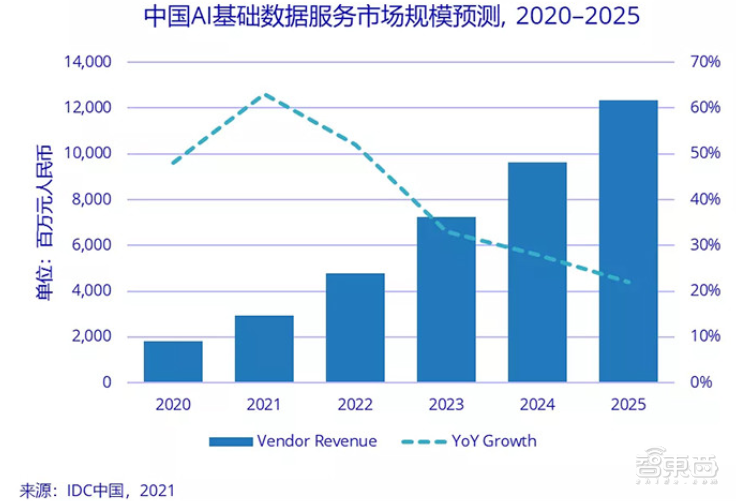 ▲2020-2025年中国AI基础数据服务市场规模预测(来源:IDC中国)
▲2020-2025年中国AI基础数据服务市场规模预测(来源:IDC中国)
但如果你认为AI基础数据服务是个纯人工作坊,那你就太小瞧这个行业的技术含量了。
尤其是多模态技术爆发以来,相应的对多模态数据需求的增长,逐步暴露了“作坊式”数据采标团队“人海”战术的短板,整个数据市场正向满足客户长尾需求演进,对服务商技术属性的要求一再加码。
如何制定与算法匹配的数据方案?如何同步采集不同模态的数据?如何处理丢失的数据?如何保证不同模态数据的精准对齐?这些都极度考验AI数据服务商的技术能力。
以获评国家工信部新一代人工智能产业创新重点任务揭榜优胜单位、国家专精特新“小巨人”企业、国家重点软件企业的海天瑞声为例,这家企业在中国AI基础数据采标服务市场中排名前列,也是A股唯一的AI数据服务上市公司,其多模态训练数据解决方案最近获得了智东西2021年度AI生产力创新奖。
根据其IPO文件,AI数据服务的核心技术可分为三个层次:训练数据生产(包括设计、采集、加工、质检),平台工具(一体化数据处理平台)以及基础研究(语音识别、语音合成、计算机视觉、训练数据集设计技术等)。
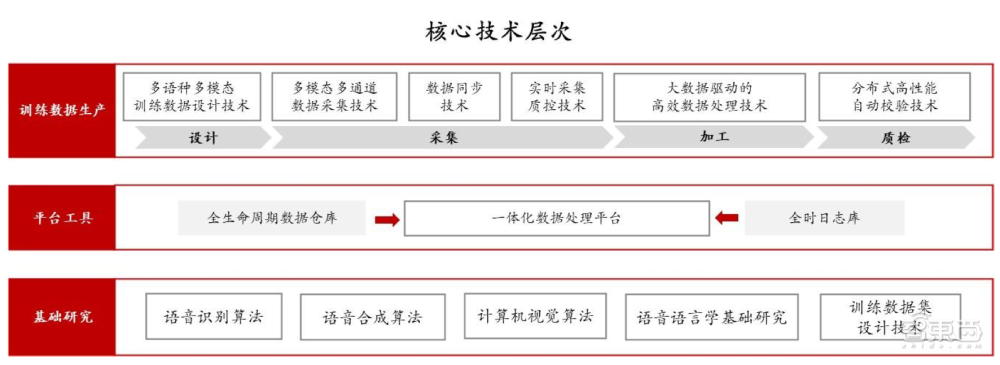
其中,在训练数据生产层,多语种多模态训练数据设计技术、采集及标注技术是高质量训练数据的生产基础。
首先在设计阶段,为了满足AI算法的需求,AI数据服务商需深入理解客户算法和应用场景,设计与之最优匹配的多模态训练数据结构,并制定合理的原料数据采集方案。
通过设计多设备采集方案,以便同时获取人发出的语音、视频画面、精细唇部动作等不同模态的信息,便于客户匹配自身算法模型框架,实现视觉、听觉等融合的多维度交互。整个过程非常考验AI数据服务商的技术储备和工程能力。
其次,在实际的采集环节中,数据损耗是常事,且造成损耗的原因迥异,而有经验的AI数据服务商能用技术快速找出解法。
我们继续以AI手语合成主播为例,采集手语数据会用到装有传感器的手套,这些手套由于并非专为手语而设计,因此在采集过程中难免会出现数据丢失的问题,一个动作很可能要做上百帧的数据修复,耗时耗力。
发现这一问题后,海天瑞声技术研发团队迅速启动应对方案,历经半个月研发出一款与硬件采集设备相匹配的自动导出、修复工具,极大提升了数据的处理效率。
修复好数据,还要应对「精细对齐」的挑战。
在虚拟数字人、智能座舱等场景中,越来越多应用开始将语音识别和计算机视觉结合,以提高理解人类意图的准确率。
像这样需用多个摄像头、传感器等设备来采集数据的应用,又带来新的难题——如何将不同设备记录的影像、声音等数据,实现同步标注对齐?
https://zhidx.com/p/314476.html
More articles on Future Tech
Pro-Iran groups lay groundwork for 'chaos and violence' as US election meddling intensifies
Created by Tan KW | Aug 09, 2024
Software innovation just isn't what it used to be, and Moxie Marlinspike blames Agile
Created by Tan KW | Aug 09, 2024
Intel's processor failures: A cautionary tale of business vs engineering
Created by Tan KW | Aug 09, 2024
China cracks down on ‘fan culture’ during the Olympics, arresting a woman for social media posts
Created by Tan KW | Aug 09, 2024
Techie told 'Bill Gates' Excel is rubbish – and the Microsoft boss had it fixed in 48 hours
Created by Tan KW | Aug 09, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts



Latest Videos





Apps


Top Articles
1
https://dividendguy67.blogspot.com
2
CEO Morning Brief
Govt Ordered to Transfer Duta Land to Semantan Estate Liquidators
3
save malaysia!
4
5
Good Articles to Share
【十年一剑之华山论剑】 EP 2 | 马来西亚经济改革之路,何去何从?美国选举,谁能坐享渔翁之利?ft. YB王建民博士 & 黄锦荣博士
6
TA Sector Research
8
Good Articles to Share
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....