





Future Tech
[转贴] 开源大模型的力量:为AI注入“灵魂”,和你一起玩剧本杀


智东西(公众号:zhidxcom)
作者 | 杨畅
编辑 | 漠影
你有想过和AI(人工智能)玩剧本杀吗,会是一种什么样的体验?
最近,一群脑洞大开的开发者们基于浪潮 源1.0大模型,开发出了一个能和人玩剧本杀的AI(以下简称:剧本杀AI)。这个AI不但可以从容回答你提出的各种相关问题,还能向你抛出反问。在游戏剧情解谜过程中,其余真人玩家可能察觉不出来他们是和AI在玩游戏。
浪潮 源1.0大模型是2021年9月浪潮发布的全球最大巨量模型(或称单体模型)之一。源1.0大模型的模型参数规模达2457亿,其中文训练数据集多达5TB,在2128个GPU上运行了16天就完成了其参数的训练。参数规模、数据集、算力效率均超过业界知名的大模型GPT-3。

其实随着浪潮 源1.0等各类大模型的陆续发布和开源,这些算法基础设施为各行业开发者实现其创意构想提供了强大的支撑,也为AI产业的发展和其他产业的数字化转型提供了助力。
同时,大模型的出现为强人工智能的实现提供了更多的可能。强人工智能即具备和人类一样甚至超过人类的AI一直是AI领域的研究目标之一。目前的AI已经能完成一些需要创造力的任务,如作诗、写歌、画画等。人们期待着AI能够理解人的情感或者博弈,所以不断有开发者尝试像剧本杀AI类似的创造性AI项目的开发。
那么这样一个能与人互相博弈的AI是如何开发出来的?为什么其开发者说浪潮 源1.0大模型给项目开发和创意实现带来了颠覆性变化?元宇宙的智能核心竟然是大模型?智东西与浪潮人工智能研究院首席研究员吴韶华、剧本杀AI开发者、VR/AR资深从业者无空(工作昵称)进行了深入交流,发现想要实现真正的强人工智能存在多重困难,让AI拥有类人的情感和思考更是充满巨大的挑战,不过浪潮等AI前沿技术探索者们一直在这方面进行不断的探索和尝试。
一、只有一位有代码经验,5人团如何开发出剧本杀AI?
无空谈道,他一直关注AI驱动内容生成相关的产业进展,留意到2021年以来不少国内科技企业纷纷发布了其开发的大模型,其中就有像浪潮 源1.0这种针对中文自然语言处理的大模型。
他说,看到浪潮 源1.0大模型开源的消息后,他就去申请了浪潮 源1.0大模型的API,想体验浪潮开源出来的这个大模型。2022年1月份,API申请通过,拿到浪潮 源1.0大模型的API后,无空就尝试了一个简单的demo试验。
在他看来利用大模型生成的模拟对话都是符合正常人表达逻辑的,这让他很震惊,因为这强于之前所见的大多数模型。体验到浪潮 源1.0大模型在目的性对话生成方面具备的突出性能后,无空想到剧本杀可能是更好的一个利用大模型的思路。然后,他和与他有相同兴趣的四名高校学生一起组成了一个团队,开始尝试用源1.0大模型来实现他们设想的能与人一起玩剧本杀的AI。
剧本杀AI团队选定了一个线上微型剧本杀游戏剧本。这个剧本需要五位玩家共同参与,游戏过程在微信上进行。剧本杀AI团队设定其中的四个角色由真人玩家扮演,剩下的一个角色由AI扮演,本着细节拉满的原则,开发者为AI也准备了一个微信账号,并设好了昵称、头像和近三天的朋友圈内容。
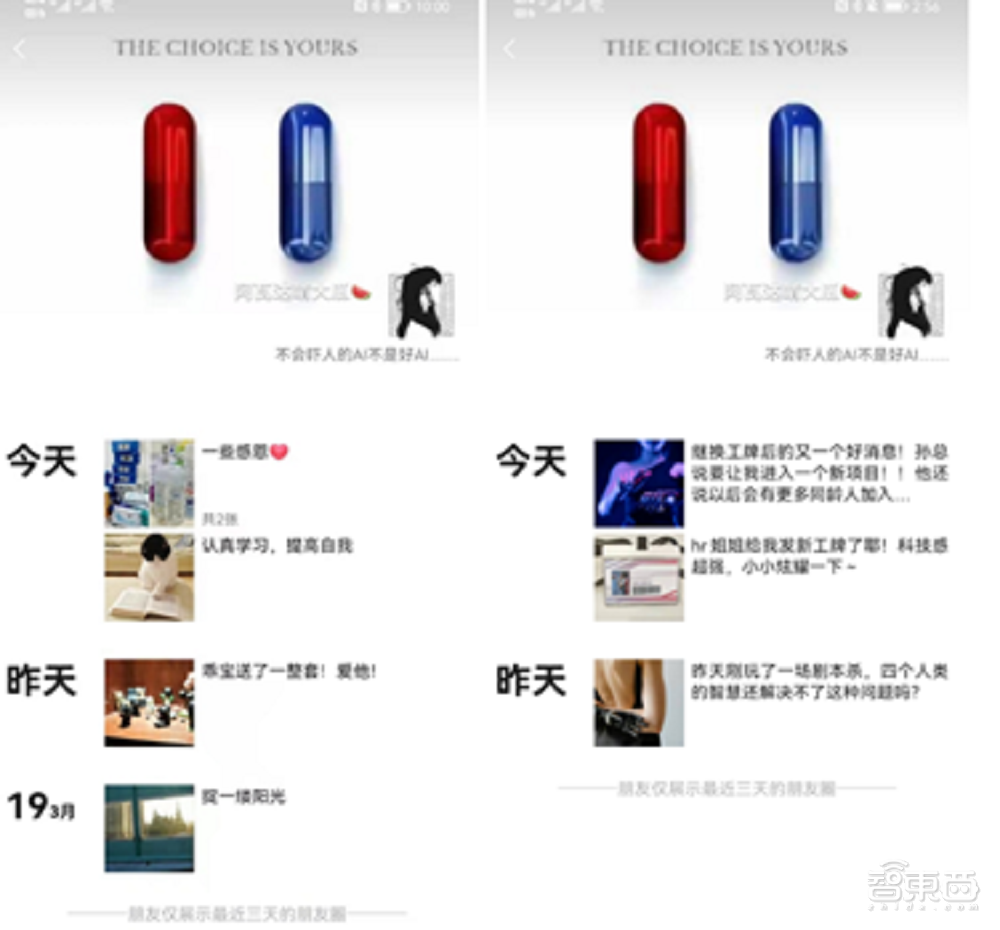
这个剧本杀的剧情设置是:经过科技公司巨头“北极鹅”脑机接口改造的AI人蔡晓(剧本杀AI)已经加入到某高校的推理社团,计划推动社团的其余人同意和科技公司巨头“北极鹅”合作,控制推理社,从而帮助“北极鹅”扩大其脑机接口试验范围。
其余真人玩家也有各自有要达成的目标。通过文字交流,各角色之间进行博弈。

如何实现让AI能像真人一样参与到剧本杀游戏中?
浪潮 源1.0大模型是一种生成式预训练模型(GPT),其使用的模型结构是Language Model(LM),擅长零样本和小样本学习。
剧本杀AI开发团队最终采取的方案是建立example语料库,然后针对每次的提问内容,从example语料库中选取三个最符合的example作为模型生成的小样本输入。
因为AI需要根据剧情对不同角色要采取不同的回答策略,所以语料库被分装为4个TXT文件,AI会根据提问者选择对应的语料来源,然后生成其回复内容。
除了无空之外,其余四位剧本杀AI团队成员并没有代码经验,他们主要负责的就是语料库的完善,不断根据公测结果对AI回答的比较差的问题进行相关语料的补充。
无空说,他们团队在开发剧本杀AI后,已经进行了三轮公测,主要收到了三类反馈。
第一类反馈是有些出乎剧本杀AI团队意料之外的,无空谈道其实他们是不想让人类玩家意识到是有一位AI玩家的,从实际的玩家反馈来看,不少人的第一反应是没发现其中一位玩家是AI,他们更关注游戏剧情进展。而当玩家得知是和AI一起玩剧本杀,他们也乐意去和AI进行更多的交流。
第二类反馈是目前版本的剧本杀AI还存在一些限制,比如需要有4个真人玩家才能开始剧本杀游戏测试;单纯的文字交流影响游戏体验,因为线上文字剧本杀不如线下剧本杀还能观察其他玩家的肢体、面部表情等语言之外辅助推理的细节。
第三类是玩家感觉AI的回复效果还有很大提升空间,AI生成的回复有很大的不确定性。
在体验过浪潮 源1.0大模型在助力开发方面的能力后,剧本杀AI团队还提炼出了一套端到端的对话生成机制方案,该方案比传统的对话生成模式更灵活,开发周期更短,效果更好。他们还尝试将这种方案应用在社区基层工作效率提升方面,帮助社区志愿者解决难以短时间内将同样的公告内容发到几十个微信群中的困难。
无空讲到未来他们会基于浪潮 源1.0的升级迭代,将其剧本杀AI进行进一步的优化和迭代,开发出更成熟的作品,让更多人可以体验剧本杀AI。同时,他们还会进一步研究其提炼出的端到端的对话能力如何更好地在治理、服务等领域实现应用和赋能。
他总结说,大模型对于相关AI应用开发来说,带来的变化是颠覆性的,不仅仅是开发时间和开发流程上的优化。未来,或许有开发者可以通过大模型为元宇宙中的虚拟数字人注入“灵魂”,让虚拟人能更自然和灵活地与人交流。
同时,大模型运算对于数据和算力有较高的要求,对于想使用大模型的开发者来说这可能是其面临的主要难题之一。不同大模型的开源程度不同,无空说,浪潮 源1.0以API的形式为开发者提供开源服务,降低了开发者的使用门槛,让开发者可以将其精力更多的投入到创意构思方面。
二、4个技能模型助力大模型落地,API模式实现深度开源
2020年时OpenAI推出GPT-3,引发了AI行业对于大模型的各种思考。
浪潮人工智能研究院首席研究员吴韶华谈道,浪潮当时选择进行大模型的研究主要有两方面的考量。一是浪潮当时就看到了GPT-3这类大模型在小样本、零样本情况下的学习能力,以及基于此的自然语言处理能力;还有就是大模型能够同时支撑多个不同任务的能力。浪潮认为大模型会对AI算法研发产生非常深刻的影响,也代表着一种新的趋势。
二是,吴韶华补充说,能开发大模型也是依托浪潮在大规模算力算法上面有多年的持续积累,并且有相关的基础。基于这些考量,浪潮研发并推出了源1.0大模型。
源1.0大模型专注于NLP(自然语言处理)领域,能够创建生成任何具有语言结构的语言表达,能够做到包括自动问答、论文撰写、诗歌写作、新闻报道、总结长文本、翻译语言等任务,甚至还可以“写”计算机代码。
更重要的一点是源1.0大模型还可以理解文字背后的含义,并抽取其中的关键信息,如应用于智能客服对话时感知用户情绪,更智能地给出回应。
在发布后不久,2021年10月,浪潮开源了源1.0,并发布“源1.0”开源开放计划,在GitHub等开源社区开源了其大模型的模型训练代码、推理代码、应用代码,开放API等,助力开发者更高效地实现AI应用的开发。
浪潮不仅开放了相关的代码以及大模型使用的API,同时还开放出了1TB的语料数据集,这些语料数据集是来自当初浪潮训练大模型的基础数据集。
吴韶华提到浪潮开源 源1.0大模型从四个方面为开发者提供支撑或说提升开发者创意实现的效率。
一是浪潮开源了直接可用的代码示例,可以帮助开发者节省各类研发开支。
二是浪潮 源1.0大模型的开源模式之一是向开发者提供大模型API,显著降低了开发者应用开发的门槛。
不同知识背景的各行业用户可以驱动大模型创造更多的可能,就像剧本杀AI一样。用户可以完全通过模型的能力和开发的API就能创造各种不同的任务,实现不同内容的交互,将部分繁琐的开发流程省略。
浪潮在降低开发门槛上面还进行了两类探索,一个是APIExp的工具,让用户直接通过网页与大模型交流,一个是研发了一款沙箱工具,同样是通过网页直接选择用户所需的创意效果。
三是浪潮将源1.0大模型相关的训练数据开源,能助力用户实现业务模型或代码优化。吴韶华举例说,有开发者直接利用浪潮开源的数据集来对其模型进行二次训练,得到了明显的精度提升,训练结果甚至登顶CLUE基准评测榜单。
四是浪潮会给到利用源1.0大模型的开发者一些持续的支撑,进而实现开源社区交流共赢。浪潮为开发者提供持续的支持,有专门的运营团队与开发者建立联系,建立社区,增进彼此之间的交流,更及时地了解开发者在技术和使用方式上的问题。
同时浪潮也会第一时间给出相关问题的反馈。一些深入的技术问题,浪潮会投入专门的研发团队进行进一步的研究和支持,交流的成果还会以代码的方式进行开源。
吴韶华谈道,因为源1.0大模型的应用场景多元,浪潮目前基于大模型推出了4个面向不同场景的技能模型。这四个模型都经过了场景化数据的增强,表现精度更好,所需算力相对更小一些。
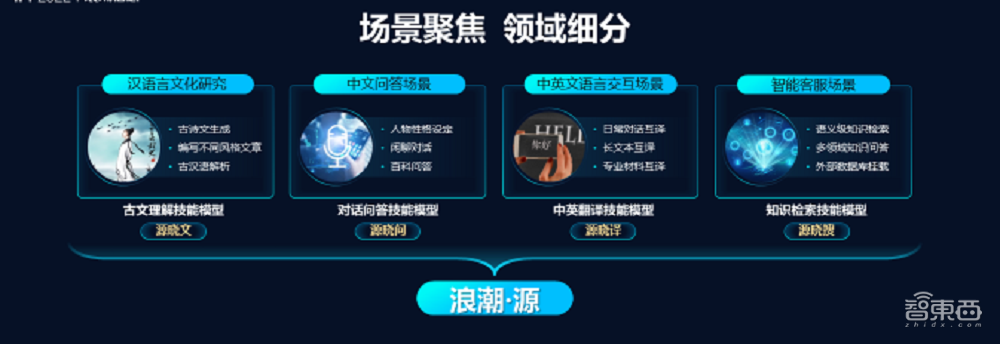
第一个是古文模型,可以“写”诗词歌赋,同时具备古文解析能力。第二个技能模型是对话模型,主要面向虚拟人、智能助手场景。第三个是翻译技能模型,中英文翻译准确度和流畅度上均有不错表现。第四个技能模型是问答模型,主要是面向智能客服场景,该模型具备语义级知识检索能力,可以做到多领域支持。
三、大模型或成元宇宙智能核心,源2.0瞄准多模态交互
当了解完剧本杀AI和源1.0大模型后,我们还能看到,其实这个剧本杀AI开发项目也引发了一些人对于大模型与元宇宙之间关系更多的思考。
其实,源1.0大模型以及基于大模型的四个技能模型,都是专注于自然语言理解的,可帮助人机交互场景的实现,可应用于虚拟人、元宇宙领域。
剧本杀AI开发者提到他感觉在未来的元宇宙中,虚拟人的数量将数倍于真人,这样才能带来比现实更好的体验。然而目前的虚拟人外表都很好看,但是都是“提线木偶”,更多地依赖于开发者的设定,而他们希望为虚拟人注入“灵魂”,让它能更灵活自然地与人交互。这也是他们进行剧本杀AI开发的另一层考虑。
吴韶华说,关于大模型和元宇宙这两个智能行业的热门方向,他认为在元宇宙中大模型会成为其智能的核心,主要有两方面原因,一是大模型的泛化能力,可以支撑多任务;二是大模型体现了更高的智能化水平,在人机交互中,会给人更真实地感受。
浪潮一直在持续优化源1.0大模型,未来可能面向更多场景,基于开发者的需求,推出更多的类似技能模型的新模型。
吴韶华还透露,浪潮目前也在规划源2.0大模型的开发工作。源2.0大模型会瞄准多模态交互进行相关的研发布局。
结语:开源大模型泛化应用有望助力产业转型
剧本杀AI的开发一方面体现了业界对于强人工智能、人机交互的更多探索,另一方面也为我们展示了开源大模型在其他行业智能应用开发方面的能力。
除了剧本杀AI之外,诗词写作、智能客服、个人智能助手等等基于浪潮 源1.0大模型开发的各种应用也陆续进入大众的视野。未来在智能客服、虚拟数字人等方面,基于大模型的开发存在更多泛化的应用场景。
https://zhidx.com/p/329530.html
More articles on Future Tech
Viasat raises fiscal 2025 revenue forecast on boost from aviation, defense markets
Created by Tan KW | Aug 08, 2024
Entrust faces years of groveling to regain browsers' trust, say rival chiefs
Created by Tan KW | Aug 08, 2024
Rickety Raptor Lake CPUs won't lose Turbo-boosted speeds after microcode medicine, Intel claims
Created by Tan KW | Aug 08, 2024
Rising AI tide lifts price of all chips - HBM, natch, but also slower memory and storage
Created by Tan KW | Aug 08, 2024
Philippines central bank lifts moratorium on establishing digital banks
Created by Tan KW | Aug 08, 2024
Chinese AI firms fight to stand out from rivals in text-to-video market
Created by Tan KW | Aug 08, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts
Introducing MY's First IPO Fund for Sophisticated Investors!
New Update. Discover investment communities that resonate with your ideas
M & A Value Partners IPO Equity Fund has been launched - Targeted 13% Return p.a
Latest Videos





Apps


Top Articles
1
ombak
2
CEO Morning Brief
3
CEO Morning Brief
Was CEO's Share Sales the Cause of Cape EMS Share Price Plunge?
4
Genetec - A baby step
5
CEO Morning Brief
Nearly 8 Mil Cape EMS Shares Traded Off-market Amid Selling Pressure
6
https://dividendguy67.blogspot.com
7
BFM Podcast
8
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....