





Future Tech
[转贴] 打通大模型训练任督二脉!国内首个千亿参数、全面开源大模型来了,还联手开发者共训


智东西(公众号:zhidxcom)
作者 | 程茜
编辑 | 漠影
智东西11月30日报道,11月27日,算力龙头企业浪潮信息发布了完全开源且可免费商用的源2.0基础大模型,包含1026亿、518亿、21亿不同参数规模,这也是国内首个千亿参数、全面开源的大模型。
浪潮信息源2.0大模型在数理逻辑、数学计算、代码生成能力方面大幅提升,且在HumanEval、AGIEval、GMS-8K等知名评测集上的表现,超过了ChatGPT的精度,接近GPT-4的精度。
.png/_zdx?a)
此外,昨天在AICC 2023人工智能计算大会上,浪潮信息还公布了源大模型共训计划,针对开发者自己的应用或场景需求,该公司通过训练数据并对源大模型进行增强训练,然后将其在社区开源。

如今,各类大模型创新应用频发,归根结底,大模型商用问题都集中于模型基础能力的提升。浪潮信息高级副总裁、AI&HPC总经理刘军谈道, 客户端碰到的较大挑战在于,模型基础能力是否能达到客户预期,而这部分的差距仍比较大。
浪潮信息是国内最早布局大模型的企业之一,2021年源1.0发布,浪潮信息打造了数据清洗、格式转化等完整流程和工具链,这也为源2.0的性能突破奠定了基础。如今,为了提升基础大模型的智力水平,浪潮信息的研发团队从算法、数据、计算方面并行创新突破,打造了源2.0。
那么,源2.0的能力有哪些提升?其背后的三大技术创新是什么?为什么浪潮信息如此坚定地选择开源开放?带着这些问题,智东西与浪潮信息高级副总裁刘军、浪潮信息人工智能软件研发总监吴韶华进行了深入交流,从源2.0出发,剖析浪潮信息在大模型时代的布局逻辑。
开源项目:https://github.com/IEIT-Yuan/Yuan-2.0
论文链接:https://arxiv.org/ftp/arxiv/papers/2311/2311.15786.pdf
一、20亿到超1000亿参数规模,性能评测接近GPT-4
大模型竞争愈演愈烈,越来越多的玩家参与其中,浪潮信息源2.0大模型的差异化优势可以用这几大关键词概括:千亿参数,全面免费开源,代码、数理逻辑能力全面升级。
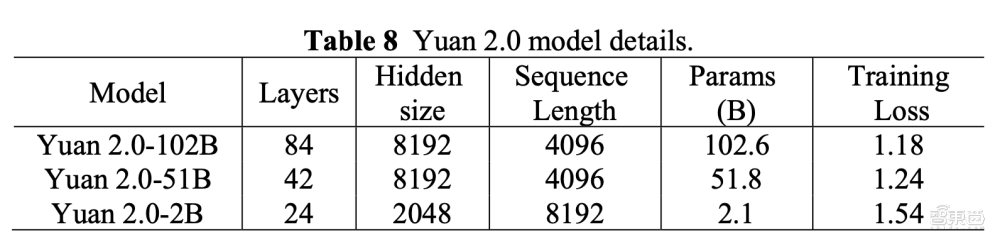
首先来看一下源2.0大模型的基础信息,这一大模型系列有三个参数规模,分别是1026亿、518亿和21亿。吴韶华谈道,浪潮信息在保证21亿参数规模模型能力的同时,让其具备更小的内存和计算开销,能直接部署到用户的移动端设备上,这对于部分终端用户而言是一个不错的选择。

在序列长度方面,源2.0-102B、源2.0-51B的序列长度为4096个tokens,源2.0-2B的序列长度为8192个tokens。
源2.0大模型具备数理逻辑、代码生成、知识问答、中英文翻译、理解和生成等能力。
浪潮信息在业界公开数据集上对源2.0进行了代码、数学、事实问答等方面的能力测试。吴韶华称,目前,源2.0在大模型应用上已经达到接近GPT-4精度的水平。
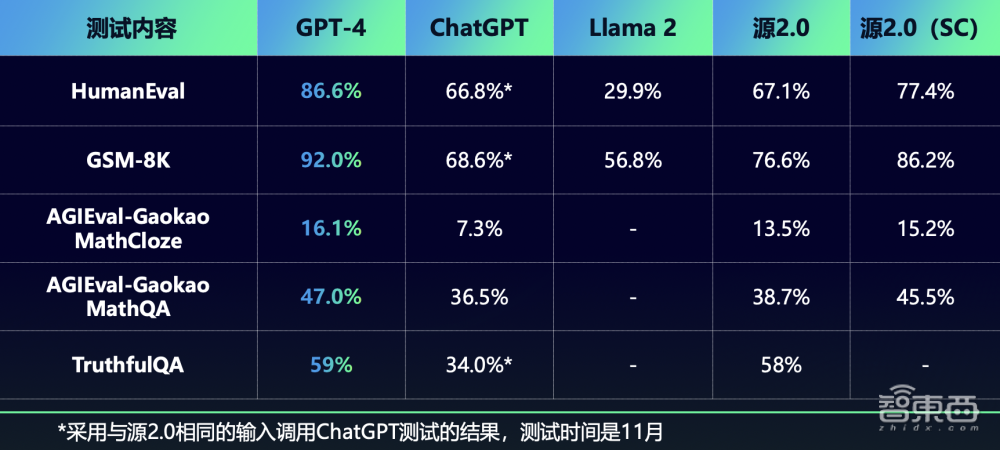
从具体的应用案例来看,当源2.0解答一道典型高考数学题时,既需要数学领域的基础知识,还需要大模型对基础知识演化、进行求解计算等,吴韶华感慨说,当时源2.0做出这道题令他们非常惊喜。

基于数学数据集GSM8K、AGIEval Gaokao-Math-QA,源2.0的能力也不逊色于ChatGPT。

在代码生成方面, 吴韶华展示了一道十分刁钻的题。他透露,这道编程题中设计较多复杂指令,需要大模型充分理解其中的相关条件,才能生成相应代码。

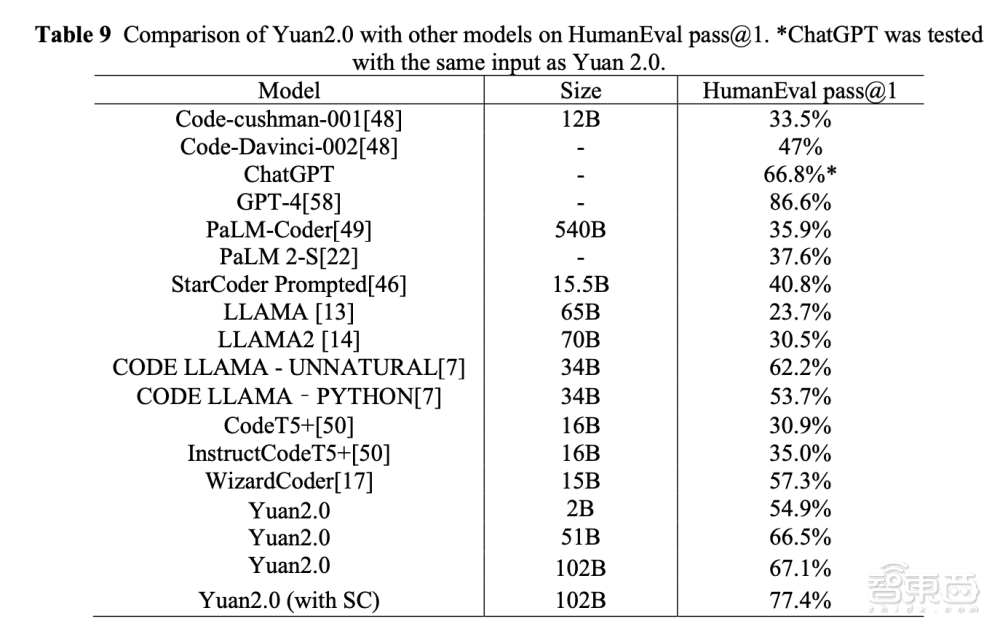
在HumanEval评测中,与ChatGPT相比,源2.0-102B的代码生成能力得分略高于ChatGPT,源2.0-51B也不相上下。
在多轮对话方面,源2.0能完成解释成语、生成七言绝句、回答成语出处等任务。

基础大模型能力不断提升的同时,大模型开始走向行业应用。可以看到,基础大模型能力的边界,正是大模型真正实现降本增效、展现其价值的关键。刘军谈道,最终用户感受到的大模型能力是其在应用层面能力的表现,这些核心能力的本质,是由基础大模型能力所决定的。
以现有的聊天机器人、AI Agent为例,这些工具带给人们生活方式、工作效率的提升,其最核心的还是基础大模型的支撑,因此浪潮信息始终聚焦于底层大模型能力的提升,将为其行业合作伙伴开发更多丰富应用提供平台。
与此同时,国内大模型产业还有一大优势就是,拥有丰富的应用场景与数据资源,这也为大模型在垂直赛道落地提供了机遇。
下一步,浪潮信息计划发布多模态大模型、大模型的长序列版本等,进一步丰富基础大模型布局。归根结底,打好基础大模型地基,在其之上构建的丰富大模型应用才能“开花结果”。
二、算法、数据、计算创新,让大模型更聪明
那么,如何让基础大模型更聪明、智商更高?
当下,大模型智力水平提升的瓶颈集中于大模型的幻觉、可解释性问题,以及算法、算力、数据这三大与大模型智能水平密切相关的关键要素,也就是算法如何创新、算力如何满足超大需求、高质量训练数据如何获取。
在此基础上,浪潮信息围绕着模型的算法结构、数据获取、训练方法进行了创新升级。
首先是算法结构的创新。不同于源1.0采用的Transformer典型架构,源2.0提出并采用了一种新型的注意力算法结构:局部注意力过滤增强机制(LFA,Localized Filtering-based Attention)。
Attention注意力机制学习输入内容之间的关系时,需要进行分词,其分词的方式如下图。但自然语言中有一种很强的局部依赖特性,如下图中“中国”和“菜”两个词。吴韶华解释道,LFA结构就是优先考虑自然语言之间的局部关系,从而提高模型的表现。

▲源2.0采用的LFA结构
LFA结构引入了两个嵌套卷积结构,输入序列通过卷积增强局部依赖关系,然后进行两两之间关联性学习,这样一来,大模型能同时掌握输入内容的全局性和局部性关系。
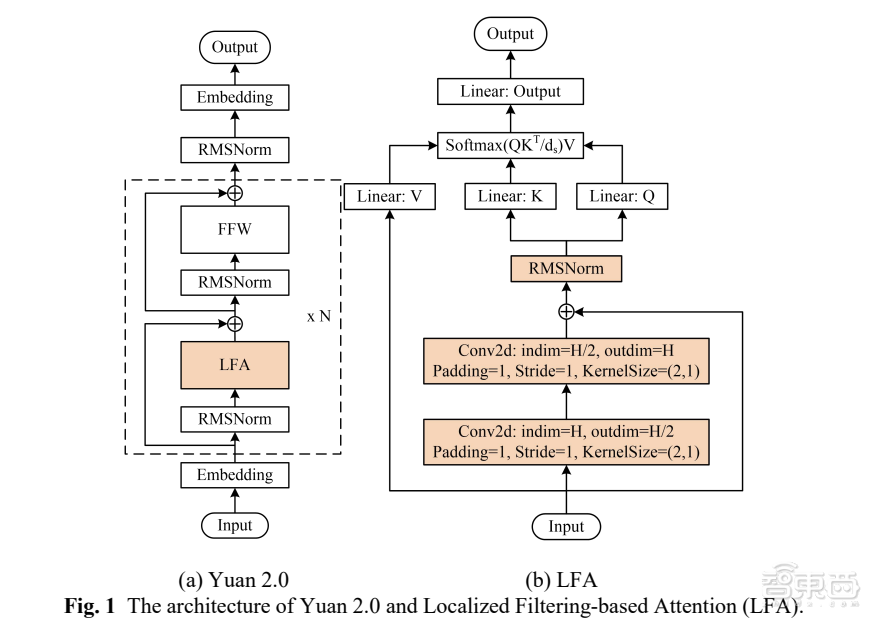
▲源2.0算法架构图
基于这一结构,源2.0可以有效提升精度并降低Loss数值,浪潮信息对模型结构的有效性进行了消融实验,相比Attention注意力机制,LFA模型精度提高3.53%。模型损耗方面,源1.0到源2.0的Train Loss降低28%, 吴韶华称,Loss数值越小就意味着大模型对于训练数据特征的学习更好。

▲源2.0 Train Loss值变化
第二大创新就是数据。有限的算力资源上,训练数据的质量直接决定了模型的性能。打造源1.0的同时,浪潮信息构建了海量数据清洗系统,将超800TB的数据压缩至5TB,但数据质量的提升仍有很大空间。因此,如何进一步提纯数据,让大模型能基于更高质量的数据进行训练,成为浪潮信息探索的一大重要方向。
吴韶华谈道,基于此,浪潮信息在构建数据集时主要考虑了书籍、论文等本身质量较高的数据,同时引入了一部分社群数据和代码数据。其中,为了得到高质量中文社群数据,浪潮信息的研发人员从12PB的数据中清洗得到10GB数据,他补充道,即便如此,这一部分数据的质量仍然不够。
浪潮信息采用了一种方式,就是基于大模型生成高质量数据,然后将这部分数据在用到大模型的训练过程中。对于大模型生成数据喂养大模型是否会有缺陷,吴韶华解释说,在他看来,这一缺陷的关键就是数据。

▲浪潮信息提高大模型生成数据质量的策略
衡量数据的质量可以通过多样性、高质量,因此,浪潮信息在构建数据时包含了尽可能多的数据类目、主题,并通过删除不带任何函数名、文档字符串或代码的示例等各项数据清理策略来获得高质量数据。
他补充说,即便其中包含大模型生成的数据,但浪潮信息通过额外构建的数据清洗流程,能将更高质量的社群、代码数据应用到模型的预训练过程中。
其次是训练方法上,浪潮信息提出了非均匀流水并行、优化器参数并行、数据并行、Loss计算分块的分布式训练方法,能降低节点内AI芯片之间通讯带宽。
.png/_zdx?a)
▲源2.0训练方法
其中,浪潮信息构建了两个性能模型,分别是张量并行、流水并行、数据并行,以及流水并行、优化器参数并行、数据并行。针对这两个性能模型,研究人员实测中发现,模型预测的数据和实际测试的数据误差非常小。采用这一分布式训练方法,大模型的性能几乎不会随带宽发生变化。
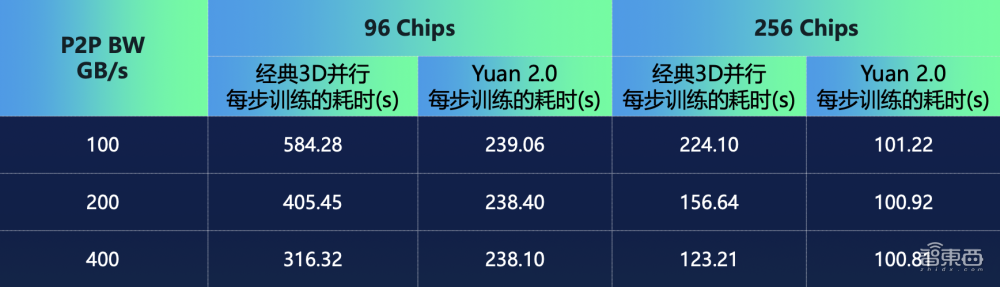
▲源2.0性能与带宽变化的关系
可以看出,从算法、数据、计算出发,浪潮信息基于自己的经验及技术积累找到了提升大模型智力水平的有效路径。
刘军谈道,去年到今年,大模型产业“粗放式经营”的发展较为明显,在这背后,浪潮信息开始探索其中的认知规律,结合认知科学、语言科学的特点,将其提炼出来,并实现算法结构的改进、数据质量的提升等。
三、开源开放,锚定大模型产业协同发展
不过,还有一大事实是,国内大模型能力与国外相比仍有不小的差距。在浪潮信息看来,开源正是国内大模型玩家追赶OpenAI,现阶段可行的路径之一。
此次浪潮信息将源2.0大模型系列全部免费开源,这也是国内首个千亿参数、全面开源的大模型系列。

开源开放的生态使得开发者可以直接调用API、中文数据集、模型训练代码等,这一方面可以降低开发者将大模型能力适配不同场景的难度,另一方面可以提升其在小样本学习和零样本学习场景的模型泛化应用能力。
刘军谈道,大模型开源最本质的好处就是,整个产业能够协同发展。当我们回顾此前成功的开源项目时会发现,其成功离不开整个社区的共同参与与贡献。
因此,面对强大的GPT-4,浪潮信息将自己的大模型全面开放出来,使得开发者在其之上构建应用时,既可以快速落地,还能在思想与技术的碰撞中,为国内产业赶超GPT-4架起一座桥梁。
他补充说,这并不意味着未来只有一家大模型能胜出,反而是未来大模型生态的建设将会更加多元化,“每个模型都会有它最擅长的能力”。
2021年,浪潮信息率先推出中文AI巨量模型源1.0,参数规模为2457亿,同时发布开源开放计划,加速大模型应用的落地应用。刘军透露,据他们不完全统计,今天国内有超过50家大模型,都使用了浪潮信息的开放数据集。
源大模型在行业应用落地的过程中,大模型的真正价值也体现在浪潮信息内部及不同的行业中。据了解,“智能客服大脑”引擎针对数据中心常见的技术问题,将复杂技术咨询问题的业务处理时长降低65%,使得浪潮信息整体服务效率提升达160%;基于源1.0,GitHub的开发人员还开发了有趣好玩的AI剧本杀平台。
▲浪潮信息开发的InService云端智控平台
下一步,依托于此前开源计划的经验积累,浪潮信息将围绕其开源社区,广泛收集开发者的需求,并打造数据平台,将大模型的能力与更多实际的应用场景相适配。
大模型要百花齐放已经成为业界共识,开源生态的出现能够在大模型能力提升的同时,找到大模型在不同行业的商业化路径。
结语:算法、数据、计算协同创新,开源打破大模型孤岛
ChatGPT的出现为AI领域的从业者展现了大模型的智慧涌现能力,国内诸多参与玩家奋起直追,国内丰富的数据资源、应用场景是大模型发展的天然优势。但基础大模型的能力如何赶超国外头部玩家也是目前一大挑战。
以浪潮信息为代表的国内大模型玩家都在探索这其中的有效路径,过去两年间,浪潮信息中抽象出一套方法论。
从技术角度来看,大模型的挑战在于设计模型结构和训练层面,经典的Transformer架构是绝大多数大模型的底层架构,但对于如何减少计算成本、提升其对于序列中顺序信息的理解,都是模型架构方面有效的探索方式。
浪潮信息率先提出的对于算法创新、高质量数据提取、训练方法的创新等,为国内基础大模型能力的进一步跃升提供了探索的方向。
与此同时,完全开源可商用的千亿级别大模型面世,或许能为更多参与者提供一种创新的思考方式,集各家之长,加速通用人工智能时代的到来。
https://zhidx.com/p/405337.html
More articles on Future Tech
China-linked group abuses Fortinet 0-day with post-exploit VPN-credential stealer
Created by Tan KW | Nov 20, 2024
Stellantis unveils technology to support flexible EV and hybrid auto production
Created by Tan KW | Nov 20, 2024
Andreessen Horowitz-backed studio Promise to start producing movies, series using AI
Created by Tan KW | Nov 20, 2024
Senator says Trump cannot ignore law requiring ByteDance to divest TikTok by next year
Created by Tan KW | Nov 20, 2024
Trump's pro-business policies to benefit India's IT sector, Wipro chair says
Created by Tan KW | Nov 20, 2024
Microsoft launches two data center infrastructure chips to speed AI applications
Created by Tan KW | Nov 20, 2024
Robinhood to acquire TradePMR for $300 million to boost advisory business
Created by Tan KW | Nov 20, 2024
Super Micro surges as AI server maker hires new auditor, seeks filing extension
Created by Tan KW | Nov 20, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts



Latest Videos





Apps


Top Articles
1
2
BFM Podcast
3
BFM Podcast
5
BFM Podcast
6
BFM Podcast
7
BFM Podcast
8
Good Articles to Share
China’s chip advances stall as US curbs hit Huawei AI product
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....