





Future Tech
[转贴] 数据中心CPU战事升温!Arm Neoverse路线图更新,新一代V2平台来了


芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西9月16日消息,昨日,Arm公布其数据中心芯片技术Neoverse系列的路线图更新。
Arm在整个基础设施市场中正快速迭代创新,其路线图包括应用于云、高性能计算(HPC)和 人工智能(AI)领域的V系列;应用于云、5G、网络和边缘领域的N系列;以及应用于5G、网络和基础设施边缘领域的E系列。
具体来看,Arm宣布推出打造数年的Neoverse V2平台,代号“Demeter”;明年其N系列产品线将迎来一次更新,目前有近20家合作伙伴正基于N2平台进行设计,新的N系列已经在开发中。同样Arm启用了E2平台,并计划更新E系列。
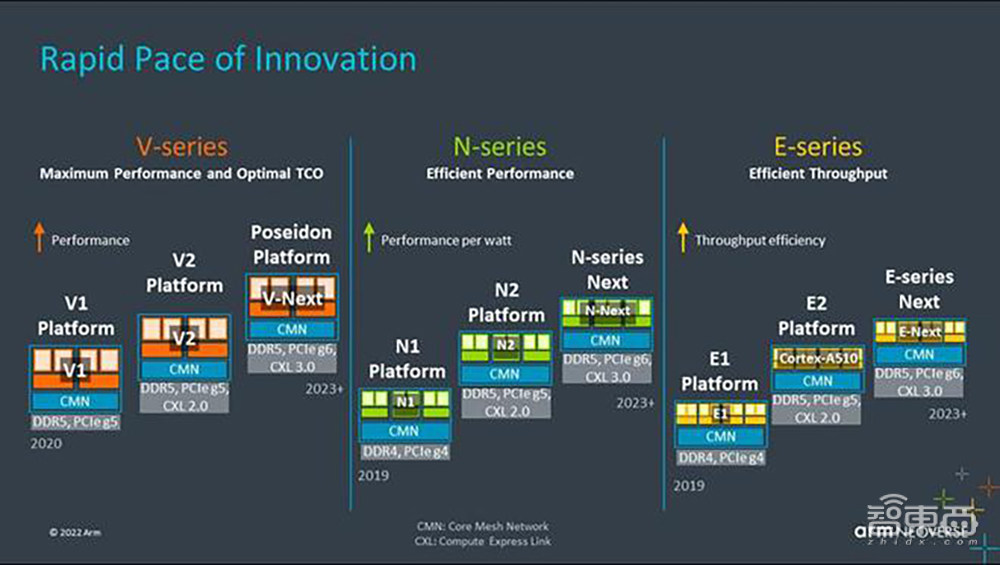
一、Neoverse V2平台发布,性能、能效、可扩展性再升级
Arm基础设施事业部产品解决方案副总裁 Dermot O’Driscoll说,在为云工作负载提供出色性能、可扩展性和效率方面,Neoverse V2具有领先优势。
单芯片性能和单线程性能是云决策者的两大关键指标。单线程性能使其了解,对 “扩展” 要求最高且性能需求大的工作负载能否迁移到Arm。高单芯片性能则使其可以通过大量运行在平台上的“横向扩展”工作负载,来实现投资价值的最大化。
超大型互联网公司十分关心TCO或TCO支出,更关注这部分TCO支出所能带来的性能,这正是他们盈利的关键。而Neoverse V系列正擅长于此。
Arm此次推出的Neoverse V2平台,得益于其与客户在其未来设计需求上的紧密合作,Arm收到的V2相关反馈包括“希望提升云工作负载的性能”、“在平衡功耗和面积的同时,继续推进单线程性能”以及“尽早发货,帮助我们快速开拓市场!”Arm已经做到所有这三点。
对于云工作负载,最基本的需求就是强大的整型性能,要具有良好的可扩展性,并且对于云运营商而言是要高效的,因为高能效使得云提供商可以提供更多的核心,并在每个服务器上托管更多客户,从而有助于降低成本。
Neoverse V2将提供市场领先的整型性能。目前用SPEC Integer Rate对预估值进行测量,并且一直利用模型中的各种云基础设施工作负载对微架构进行调整,Dermot O’Driscoll称,整个系列的成果都令他们十分兴奋。
除了整型可扩展性能之外,现代云应用程序还拥有大型工作数据集。如果能在接近CPU的位置保留尽可能多的数据,将是一个巨大的优势。为此Arm在Neoverse V2中增加了2MB的专用L2缓存。这比V1上的L2大1倍,且使用延迟的负载不变,能让MySQL和Memcached等云应用获得显著的性能提升。
同时,对于像HPC之类正快速迁移到云端的工作负载而言,矢量性能很重要。Arm在Neoverse V2上已完成从SVE到SVE2的过渡,SVE2可以帮助满足更多非HPC ML类型的工作负载,同时添加了更多加密指令。Arm还将矢量引擎重构为4通道的128位,并对微架构进行了调整,以提高其有效吞吐量。
在系统层面,能够支持大量DRAM十分重要,这在IO方面,他们希望能够跨IO总线连接GPU、TPU和基于NVMe的SSD,所以总线既要快又要支持高带宽。
通过V2平台,合作伙伴已能利用支持Neoverse N2的系统IP底板,包括CMN mesh、MMU、GIC和NI非一致性互连。CMN-700 mesh互连支持每块裸片最高512 MB的系统级缓存,而且当前基于CMN-700的设计中增加了每个核心的系统级缓存,从而提升了云原生工作负载性能。
CMN-700支持2.5D设计,其平台可以随时过渡到3D,能将每个核心的缓存水平推向新高。CMN-700还支持高达每秒4TB的mesh带宽。一个HBM2e内存栈需要达到每秒0.5TB的带宽。
客户还想要特定于Armv9的安全功能和极具竞争力的系统平台。对此,Neoverse V2中引入了一些关键的Armv9安全增强功能,主要目的是防御内存攻击,这也是最常见的攻击类型。
二、Arm Neoverse新增产品的四项关键原则
Arm Neoverse新增的产品是基于几项关键原则所打造,将继续提供基础设施市场所需的性能、效率和专用处理能力。
首先是可扩展效率。两年前,Arm推出了V、N 和E系列核心设计原则。自那时起,大量基于此类计算基础的解决方案陆续面市。
另一个关键原则是技术领先地位。Arm已创下了多项行业第一:第一个总内存带宽超过每秒1TBffg’gv’b的CPU;第一个单块裸片上能配置超过100个核心的CPU,核心数达到128个;第一个将DDR5 和PCIe Gen5.0推向市场的CPU;第一个在 SPEC CPU 2017基准测试中打破500整型跑分的CPU……
第三是快速创新的步伐。今天,这类CPU大多仍以单块芯片形式交付,但这种情况正在迅速转变。采用Graviton3的云gg服务今年发布GA版本,其中Graviton3使用7个 Chiplet。加速计算将计算Chiplet与加速器Chiplet相结合,如NVIDIA的Grace Hopper超级芯片。正因如此,Arm才会成为UCIe的创始成员。
在推动各种重要互连技术的过程中,Arm及其合作伙伴都参与其中。多年来,Arm一直致力于开发和增强AMBA CHI,这是实现高速、低延迟的芯片到芯片通信的重要协议。如今,Arm的合作伙伴使用CMN系列中的AMBA CHI,Arm正与UCIe社区展开合作。
Arm也是CXL的一员,将其视为桥接芯片到芯片解决方案的关键互连技术,例如将扩展内存、多个GPU或TPU连接到一个计算节点上。
Arm基础设施事业部产品管理高级总监Brian Jeff透露,目前这一代Neoverse的系统总线支持的是CXL 2.0,希望在新一代的系统总线中能支持CXL 3.0,届时有望通过Neoverse V2来使用其新一代的总线技术。据他观察,目前内存扩展用例对CXL 2.0仍有很多需求,并预计在超大规模市场中会有一些设计出于这些目的来使用CXL。
据介绍,当Arm的合作伙伴选择可扩展效率计算基础,并使用CMN等互连技术来增添其专用处理能力时,即可实现这一成果。这体现了解决方案的多样性,而且只有在Arm架构上才能实现。
Arm Neoverse平台的第四条也是最后一条原则是,构建独一无二的开发者生态系统。Arm SystemReady旨在打造一个软件可“开机即用”的世界,Arm将持续与生态系统和开源社区展进行优化工作。
三、Arm Neoverse今年取得多个里程碑式成就
Arm高级副总裁兼基础设施事业部总经理Chris Bergey还回顾了今年Arm Neoverse取得的多个有里程碑意义的成就,包括:
1、在全球范围内,Arm现已被用于各个主要公有云,包括 AWS、微软、谷歌、阿里巴巴、甲骨文等科技巨头。这意味着,世界各地的每一位开发者现在都可获取Arm Neoverse。
2、Arm在5G RAN领域无处不在。在世界移动通信大会上,戴尔与Marvell宣布合作,高通也与乐天、HPE 达成了合作。他们与诺基亚、联想、三星等公司正合力酝酿许多更加激动人心的项目。
3、NVIDIA发布了面向AI及高性能计算(HPC)的 Grace。
4、逐步迈入更为传统的“企业”领域。VMware运用DPU开展Monterrey项目。RedHat的OpenShift支持Arm架构。SAP HANA正将其云基础设施迁移到AWS Graviton上。6月,HPE推出了ProLiant第11代平台,搭载了基于Arm Neoverse的Ampere Altra处理器。
“我们已经达到了转折点,来全新的开端。Arm 架构是全球计算未来的基石!”Chris Bergey说。
在中国市场,Arm Neoverse同样势头强劲。除了大企业外,一些初创公司也开始基于Arm Neoverse设计芯片。Arm基础设施事业部全球副总裁邹挺(Frank Zou)在接受采访时谈道,比如遇贤微电子、鸿钧微电子致力于云原生服务器CPU的开发,云豹智能主要针对DPU领域,他们正在开发基于Neoverse N2的产品。
Arm的V系列核心、AWS Graviton3中的Neoverse V1和NVIDIA Grace中的Neoverse V2将提供目前市场上最佳的单线程性能。Ampere Altra Max和阿里的倚天710等将继续提供最佳的单芯片吞吐量。
Dermot O’Driscoll还谈到Arm如何建立软件生态优势。Arm多年来一直在努力实现并优化在Arm架构上运行的全栈解决方案,从架构和IP到技术库、运行环境和编译器,已启用了各种基础设施软件来提取最大性能。
下一个发展趋势是机器学习(ML)。就像Java 在如今的云工作负载中占据大比例一样,ML正逐渐成为未来的首选工作负载。在ML中,Arm可以对BERT实现同样的启用。其V1核心拥有一组专门用于增强ML应用程序性能的功能。
Arm Neoverse在架构方面添加了Bfloat16(BF16):调整了V1、N2以及后续设计的微架构,旨在通过BERT提高BF16的执行,为Arm计算库(ACL)增加BF16支持,将ACL集成到oneDNN ML框架中,oneDNN框架与Tensorflow搭配使用以运行BERT。
基于V1核心的AWS EC2 C7g上运行BERT,并将其与使用最新Xeon核心的C6i进行对比,在Arm架构上经BF16优化的堆栈性能比英特尔高出80%。在V1添加的BF16和Int8 MatMul意味着ML模型可以更紧凑地植入内存,只需更少的内存带宽,使Graviton3的ML性能达到Graviton2的3倍。
当被问及如何看待RISC-V指令集架构的竞争,Dermot O’Driscoll认为,如果RISC-V想要在终端或云应用中更具竞争力,这将需要他们在架构、软件以及标准上进行多年的投资,并且很可能还需要具备类似于Arm的治理模式。
结语:Arm为云平台提供了可持续发展的另一条道路
可以看到,Arm并非为传统市场构建标准产品,而是与云、HPC和无线基础设施方面的主要市场参与者密切合作,因此能够真正得了解他们的工作负载和挑战,针对特定市场需求实现定制化。
从手机、电脑、AR/VR头显、物联网设备、汽车到云计算,Arm已随处可见,全球的开发者均能获取。如今,Arm不仅支持多云平台和企业都想要的负载平衡和冗余,还为开发者提供另一可持续发展的道路。
https://zhidx.com/p/345660.html
More articles on Future Tech
Datacenters bleed watts and cash – all because they're afraid to flip a switch
Created by Tan KW | Sep 20, 2024
Europe's largest city council: Oracle ERP allocated £2B in transactions to wrong year
Created by Tan KW | Sep 20, 2024
Nokia says German court rules in its favour in Amazon patent dispute
Created by Tan KW | Sep 20, 2024
Bank of Canada: AI could boost inflationary pressures in short-term
Created by Tan KW | Sep 20, 2024
Disney kicks Slack to the curb, looks to Microsoft Teams for a happily ever after
Created by Tan KW | Sep 20, 2024
Constellation inks power supply deal with Microsoft, plans to restart nuclear plant
Created by Tan KW | Sep 20, 2024
While HashiCorp plays license roulette, Virter rolls out to rescue FOSS VM testing
Created by Tan KW | Sep 20, 2024
Analysis: Brazil’s online gambling craze may be hitting consumer spending
Created by Tan KW | Sep 20, 2024
Crack coder wasn't allowed to meet clients due to his other talent: blisteringly inappropriate insults
Created by Tan KW | Sep 20, 2024
Discussions
Be the first to like this. Showing 0 of 0 comments
Post a Comment
Featured Posts
Introducing MY's First IPO Fund for Sophisticated Investors!
New Update. Discover investment communities that resonate with your ideas
M & A Value Partners IPO Equity Fund has been launched - Targeted 13% Return p.a
Latest Videos





Apps


Top Articles
1
Stock Market Enthusiast
YTLPOWER: Reversal Ahead? Hammer + MACD Crossover Pattern Emerging... KingKKK
2
Trendindicator
3
4
5
6
8
TA Sector Research
#
Stock
Score
Daily Stocks
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
Stock Name
Last
Change
Volume
MQ Trading Signals
Stock
Time
Signal
Duration
Stock
Time
Signal
Duration
Featured Advertisers / Partners



Ride The Bull Short The Bear
CS Tan
4.9 / 5.0
This book is the result of the author's many years of experience and observation throughout his 26 years in the stockbroking industry. It was written for general public to learn to invest based on facts and not on fantasies or hearsay....